7-4 Four types of Detection ( Traffic )
Learning Objectives
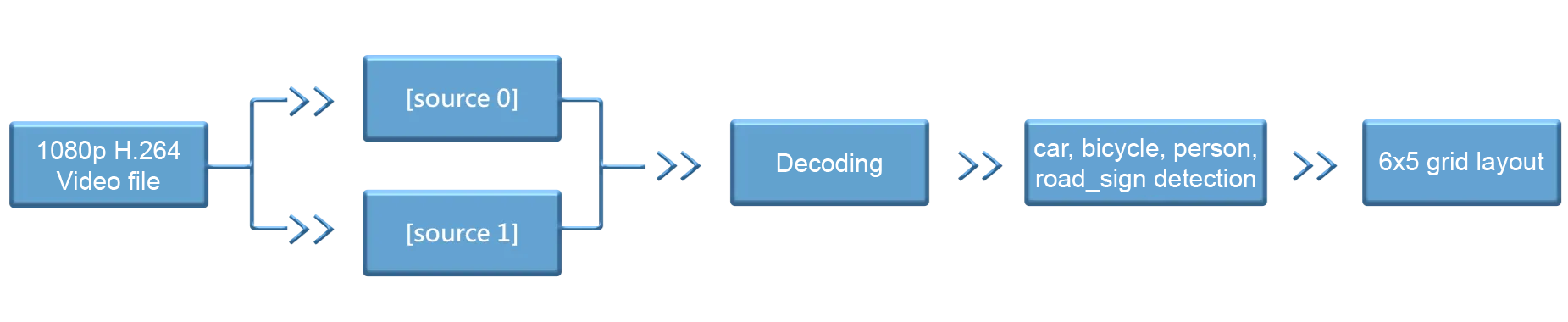
We run DeepStream-app (the reference application) using a single 1080p H.264 video file as input. Through two MultiURI sources, we replicate 30 instances of the decode + inference pipeline and display the results in a 6×5 grid layout. The model detects four object classes appearing in the video—car, bicycle, person, and road_sign—and overlays bounding boxes on them for display.
Run the example
The first run requires TensorRT optimization, which takes about 10 minutes. If the container is deleted and a new one is created, TensorRT optimization will need to be performed again.
cd /opt/nvidia/deepstream/deepstream-7.0/samples/configs/deepstream-app
deepstream-app -c source30_1080p_dec_infer-resnet_tiled_display_int8.txt
During the process, the following WARNING messages (as shown in the image) may appear. These indicate that the model is being optimized, so please do not interrupt.
 Results:
Results:

Reference:
Quickstart Guide — DeepStream documentation