10-15 英文語音轉文字功能範例教學
在體驗了從人形、多特徵到工安防災等豐富的「影像辨識」功能後,本章節我們將解鎖 NexVDO SDK 的另一項強大潛能——「音訊處理」。
我們將導入專門針對英文語系訓練的語音轉文字模型,讓您的軟體不僅能「看懂」畫面,還能「聽懂」聲音,將接收到的即時語音串流瞬間轉換為文字字幕!這項技術非常適合應用於跨國視訊會議紀錄、英語遠距教學即時字幕,以及影片自動上字幕等智慧場景。
學習目標
透過本章節,您將學會:
1. 針對音訊分析場景,配置並載入專屬的英文語音轉文字模型。
2. 理解從「影像資料流」切換到「音訊資料流」的核心流程差異,並使用 SDK 內建機制直接渲染畫面。
3. 學習在程式中註冊專屬的 AI 回呼函式 (QDEEP_REGISTER_OBJECT_DETECT_CALLBACK) 相關字樣)。
4. 實作 UI 介面擴充,將辨識出的文字即時更新並顯示於 Qt 的標籤 (QLabel) 上。
準備工作
要讓 AI 具備英文聽寫能力,我們必須為它換上專注於語音辨識的「大腦」。這次的模型包包含了多個設定、權重與關聯的文字檔,因此檔案數量會比較多。
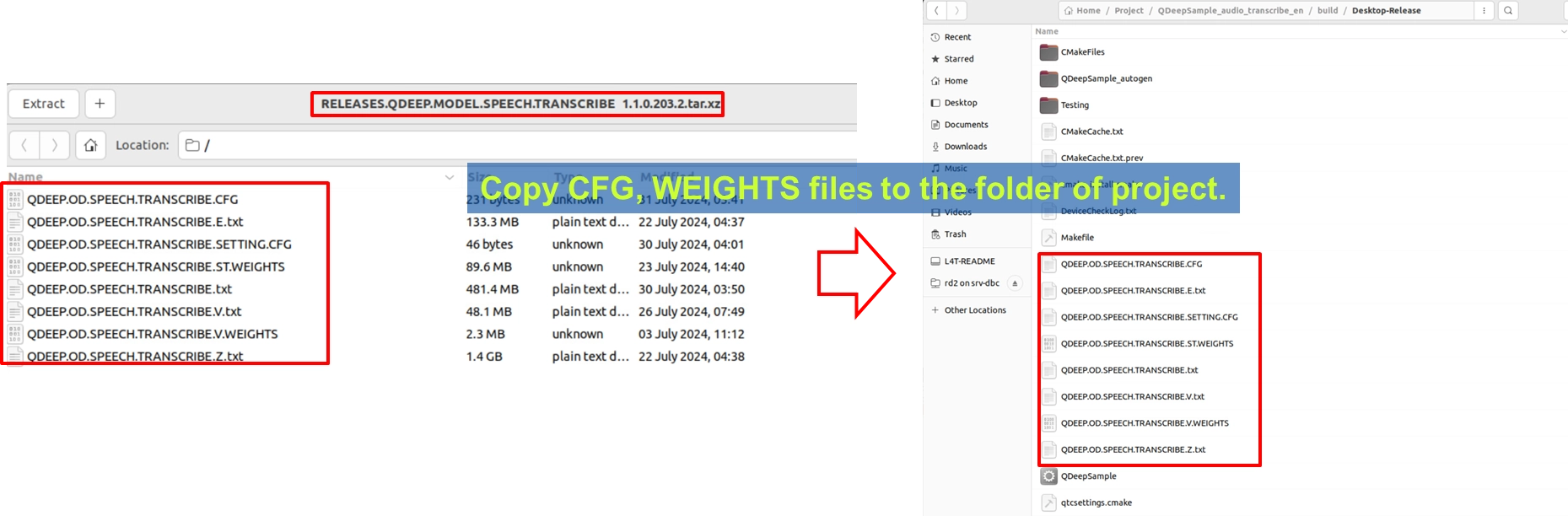
1. 請找到語音轉文字模型壓縮檔(檔名可能標示為 RELEASES.QDEEP.MODEL.SPEECH.TRANSCRIBE.
2. 將其解壓縮後,把裡面的 QDEEP.OD.SPEECH.TRANSCRIBE.CFG ( 設定檔 ) 以及所有對應的權重檔 (.WEIGHTS) 與字典/文字檔 (.txt, .SETTING.CFG) ,一併複製到您 Qt 專案的建置輸出目錄下(與執行檔同層)。
核心觀念解析:從「影像」到「音訊」的流程轉換
在我們正式修改 API 之前,必須先釐清一個極度重要的核心觀念。因為之前我們都是講解影像的處理,而這次是講解聲音!
• 過去的影像流程 : 我們是透過 on_video_decoder_broadcast_client_callback 來攔截解碼後的 NV12 影像數據,並呼叫 QDEEP_SET_VIDEO_OBJECT_DETECT_UNCOMPRESSION_BUFFER 將畫面餵給 AI。
• 全新的音訊流程 : 由於模型是針對聲音進行辨識,使用者必須將「音訊數據」發送給偵測器。因此,我們必須改從負責接收聲音解碼的 on_audio_decoder_broadcast_client_callback 中去攔截純淨的 PCM 音訊數據。並使用專為音訊設計的新 API (QDEEP_SET_AUDIO_...) 來傳遞這些聲音特徵!
➤ 接收端的音訊回呼函式可以回顧 : 10-9 RTSP 串流接收端功能範例教學
核心 API 要怎麼改?
了解流程差異後,我們來看看需要修改與新增的核心 API:
• 模型配置 Enum 的改變 : 在 QDEEP_CREATE_OBJECT_DETECT 中,請換成專屬的 QDEEP_OBJECT_DETECT_CONFIG_MODEL_SPEECH_TRANSCRIBE_EN 。
• 註冊語音辨識結果 : 我們需要透過 QDEEP_REGISTER_OBJECT_DETECT_CALLBACK 取得辨識結果。
QDEEP_CREATE_OBJECT_DETECT
這是建立 AI 引擎並載入大腦(模型)的最關鍵 API。使用者必須透過此 API 初始化偵測器。

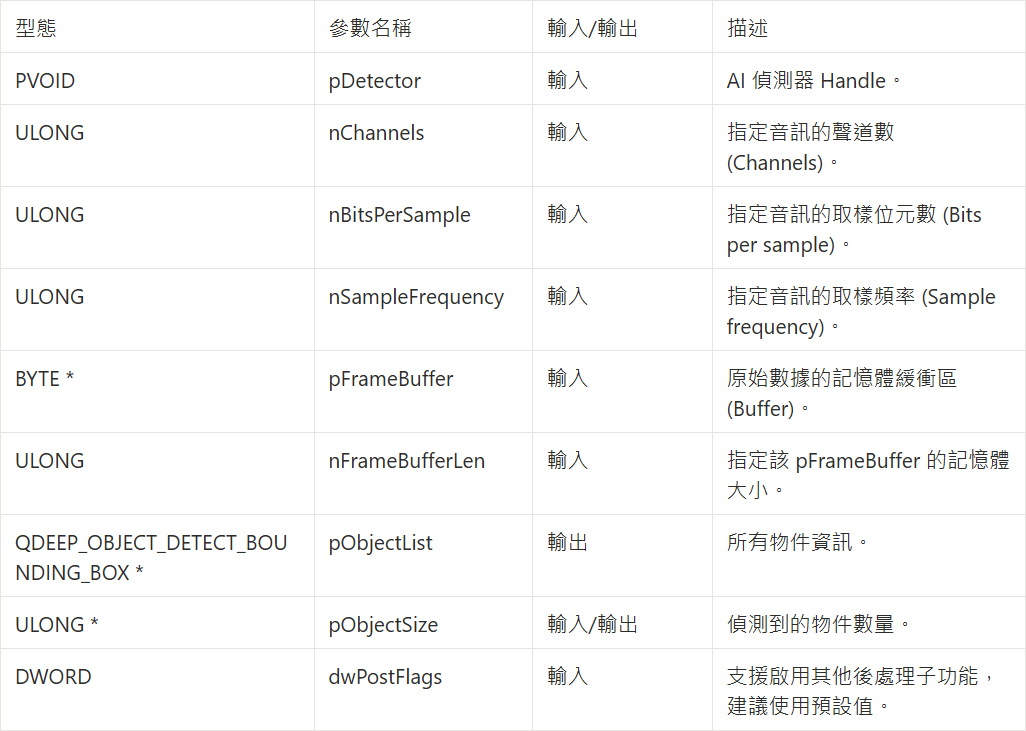
QDEEP_SET_AUDIO_OBJECT_DETECT_UNCOMPRESSION_BUFFER_EX
我們要在 on_audio_decoder_broadcast_client_callback 中呼叫它,將聲音數據源源不絕地提供給 AI 偵測器。比起影像,音訊需要傳遞不同的物理參數:
資料回呼-拿到聲音辨識結果
• 註冊 API : QDEEP_REGISTER_OBJECT_DETECT_CALLBACK
• 觸發時機 : 當 AI 引擎聽完一段話並完成辨識時,就會主動透過這個 Callback 將英文句子傳遞給我們。
• 回傳的情報參數 (PF_OBJECT_DETECT_CALLBACK) :
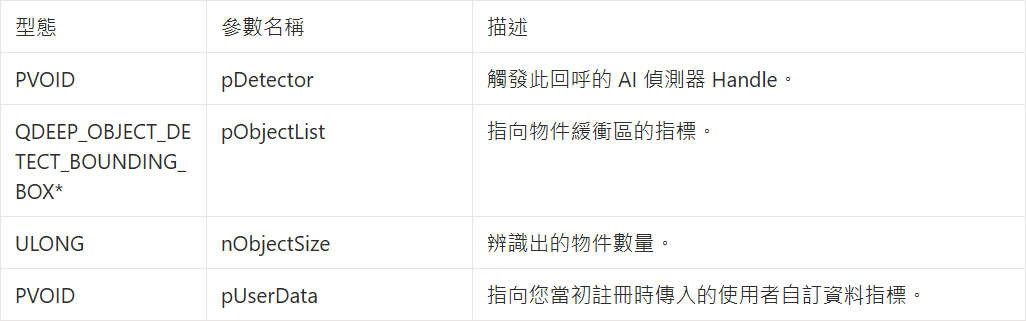
QDEEP_OBJECT_DETECT_BOUNDING_BOX 結構體
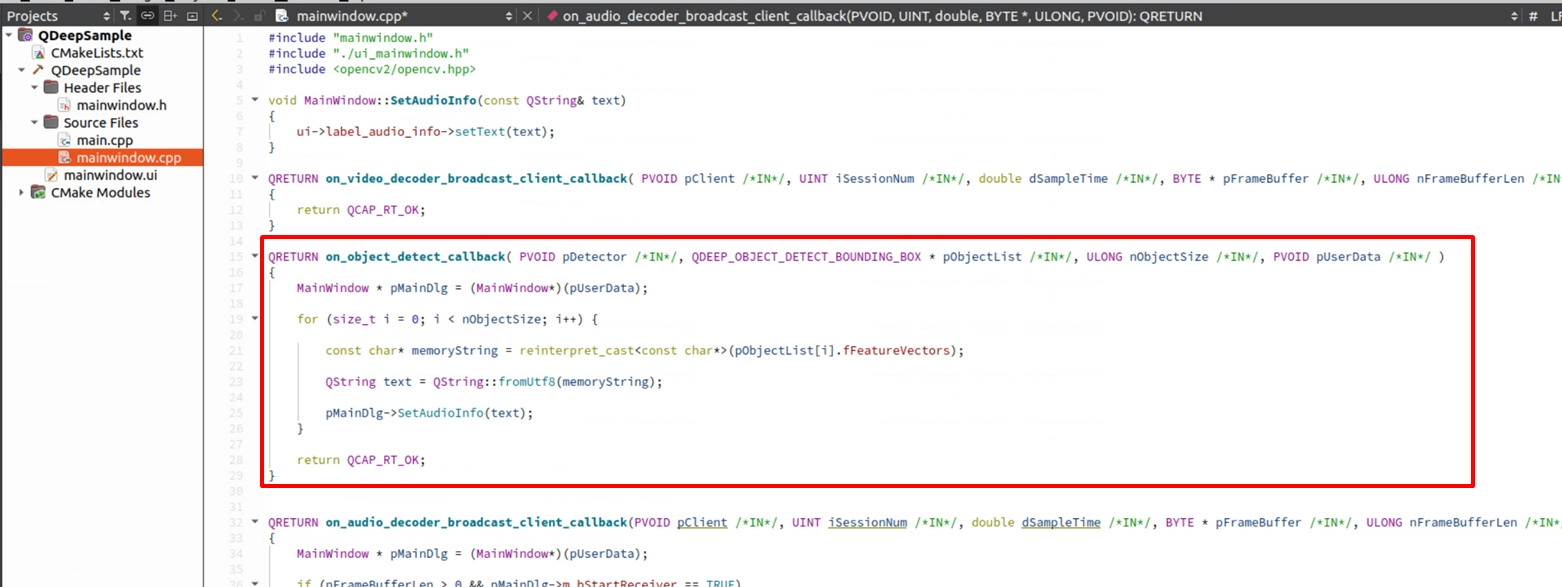
在語音轉文字模型中,SDK 會透過此欄位帶出語音辨識結果相關資料,AI 引擎會在這個結構體中透過 fFeatureVectors 參數將語音辨識結果供我們提取!

撰寫核心程式碼
請開啟您的專案,我們將進行關鍵的微調:
新增字幕顯示介面 ( QLabel )
因為這次的結果是「文字字幕」,請打開您的 mainwindow.ui,在畫面下方新增一個 QLabel 元件,並將其命名為 label_audio_info ,用來專門顯示語音辨識的英文結果。
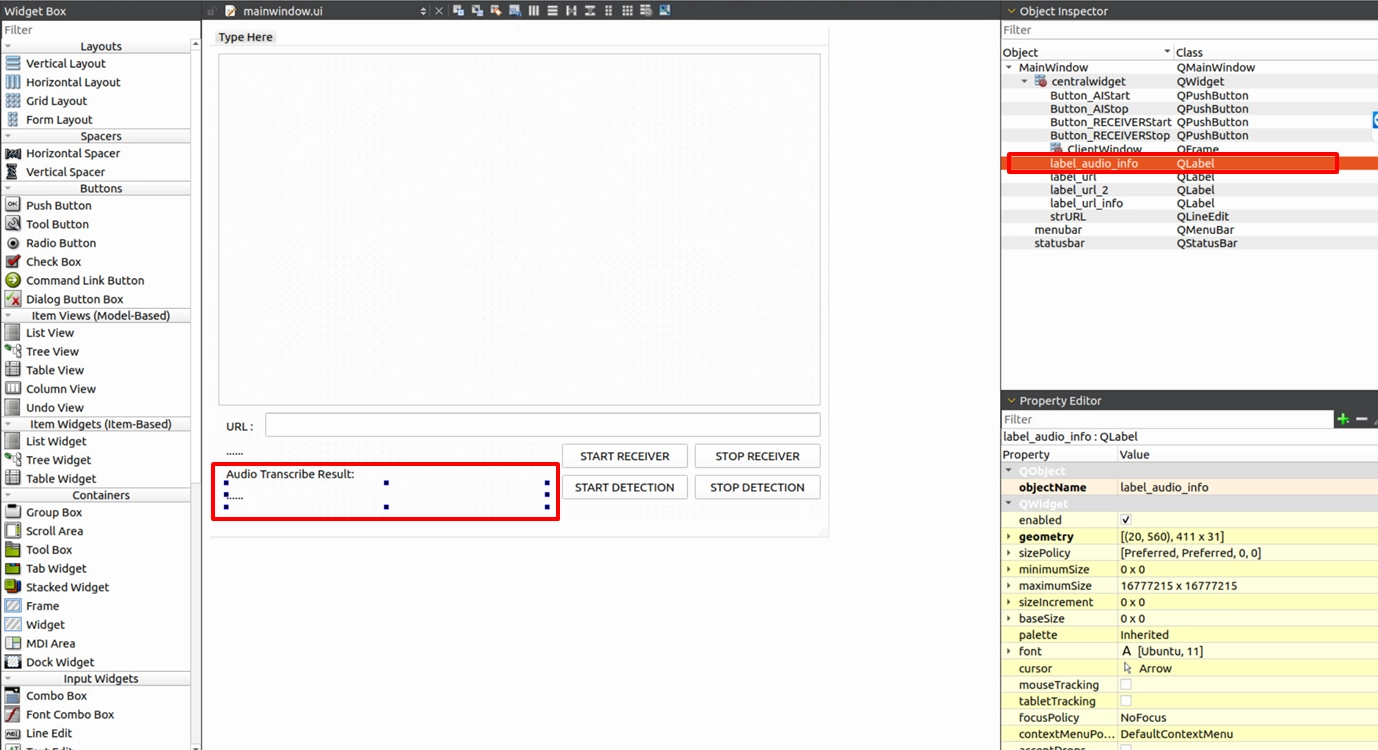
接著,為了讓全域的 Callback 能夠安全地修改 UI,我們需要在 mainwindow.h 中宣告一個公開的專屬函式:
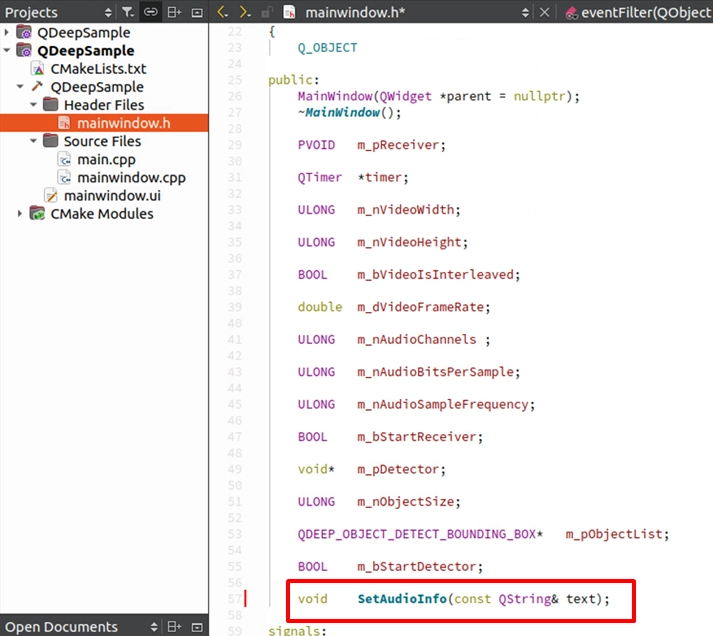
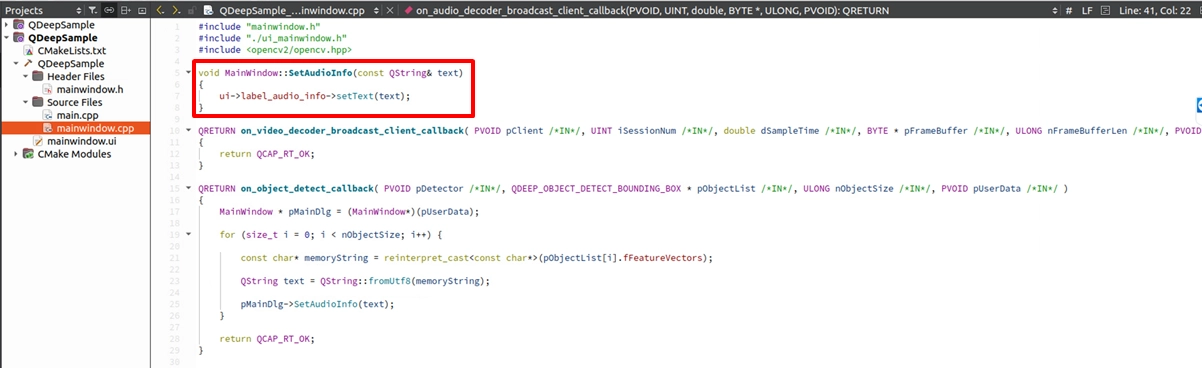
並在 mainwindow.cpp 中實作它,邏輯非常單純,就是把收到的字串設定給標籤:
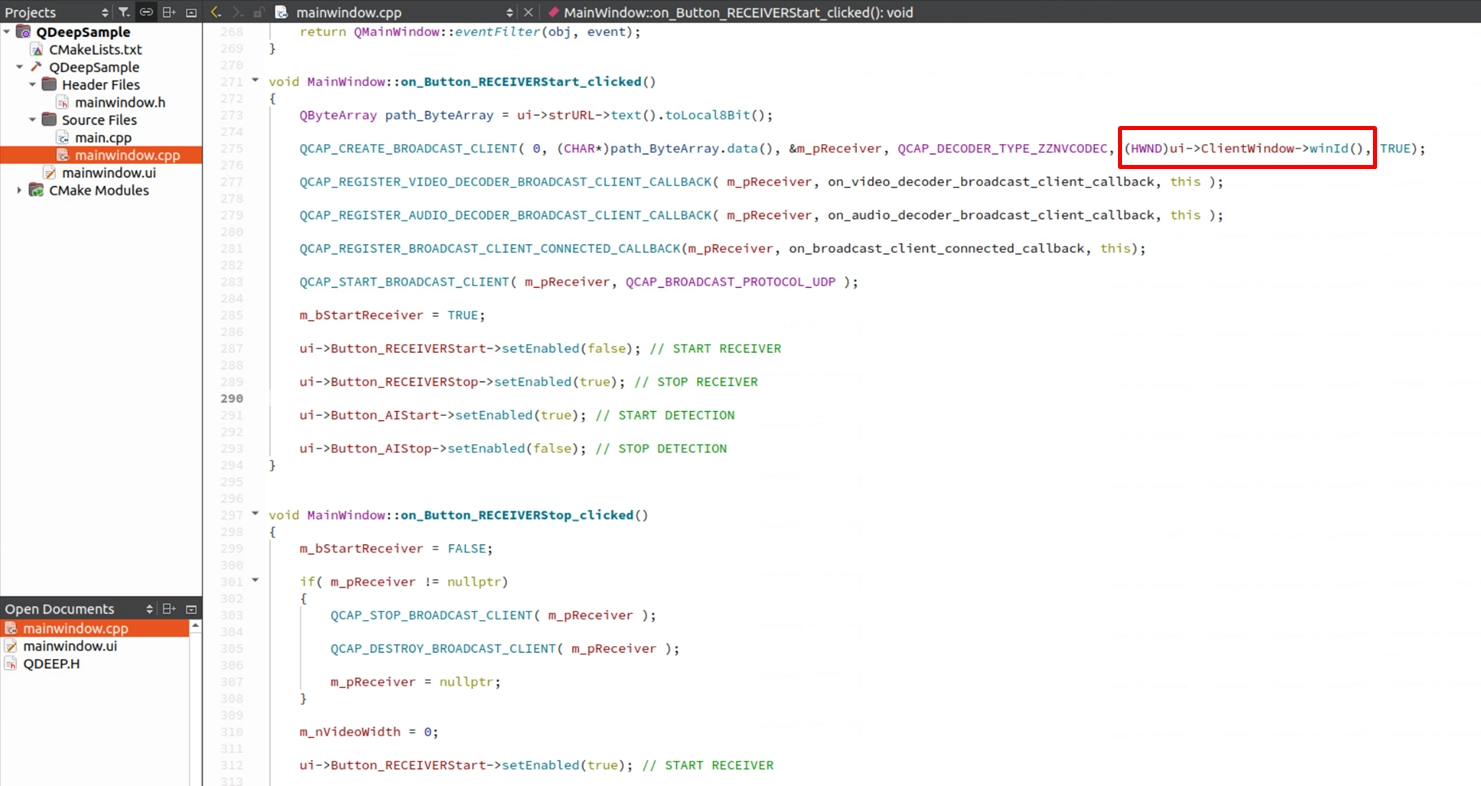
綁定 SDK 原生畫面渲染
在前面的章節中,為了在畫面上畫出 AI 追蹤框,我們必須將原始影像攔截下來,並大費周章地轉為 OpenCV 格式 (cv::Mat) 再用 QPainter 繪出。但在本章節中,因為我們只針對「聲音」進行辨識,影像的部分不需要加工,所以我們可以直接利用 RTSP Client API 的原生功能,把 UI 的顯示窗口綁定給 SDK,讓它自動幫我們播放畫面!這將大幅簡化我們的程式碼。
宣告音訊資訊變數
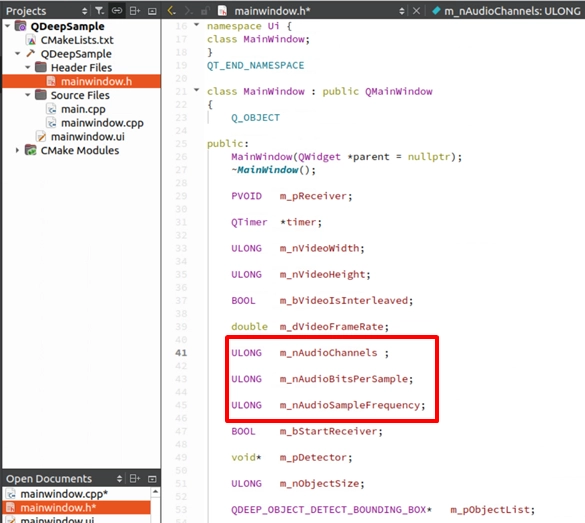
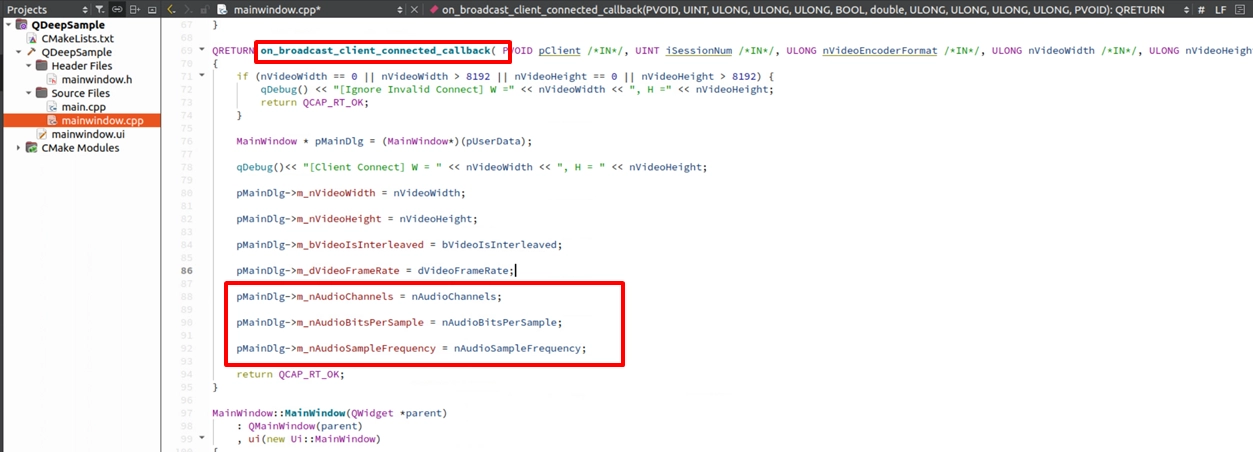
模型載入與註冊 Callback

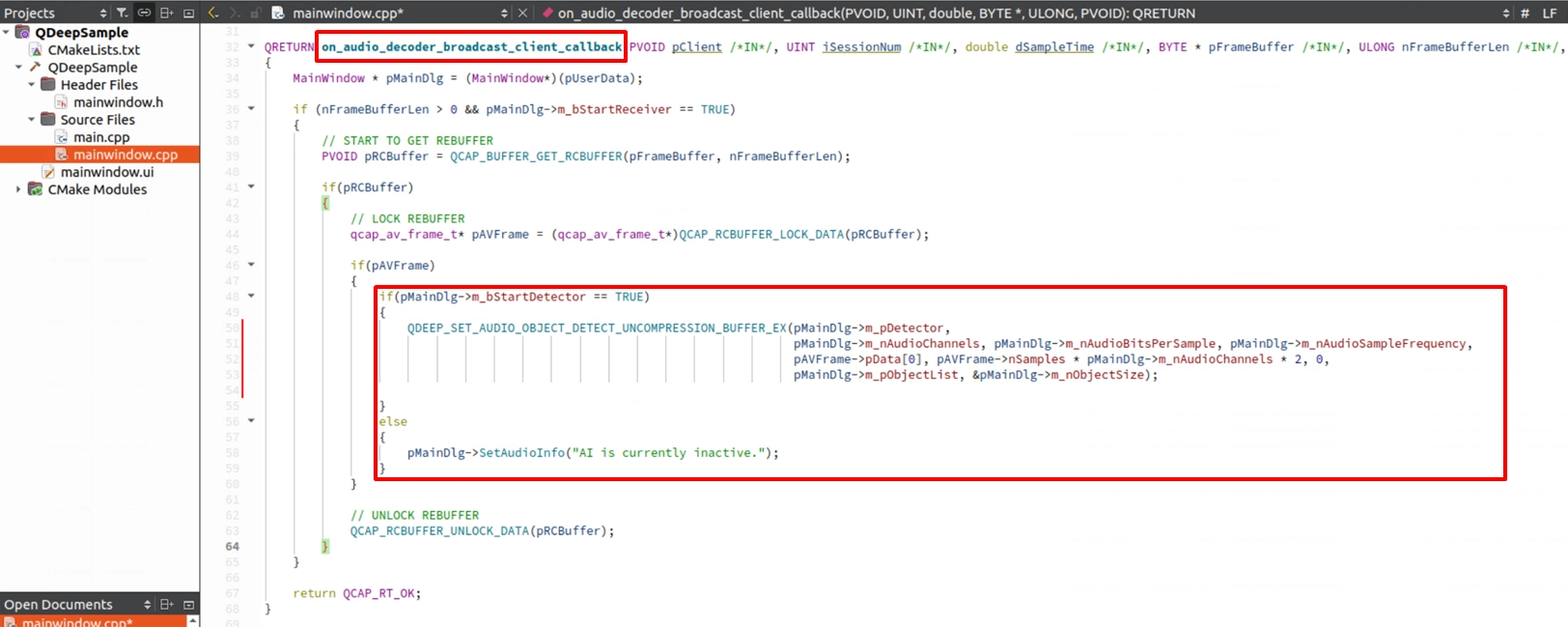
在 Audio Callback 中餵入聲音
找到 on_audio_decoder_broadcast_client_callback 函式,利用 QDEEP_SET_AUDIO_OBJECT_DETECT_UNCOMPRESSION_BUFFER_EX ,把攔截到的 PCM 聲音數據 (pFrameBuffer) 、聲道數、取樣率等參數餵給 AI 引擎。然後在註冊函式中專屬的回呼函示內取得語音辨識結果,並傳給 Qlabel 進行顯示結果;但如果沒有開啟 AI 功能的時候,label_audio_info 就會顯示預設的字串。
在 callback 取出辨識結果並更新 QLabel
最終驗證
準備好迎接您的第一個 AI 英文聽寫助理了嗎!現在,請按下左下角的 「Build and RUN」 執行專案:
1. 輸入一段具有「英文人聲說話」音軌的影片 RTSP 網址,點擊 START RECEIVER 開始接收串流。
這時候畫面會由 SDK 自動且流暢地直接繪製在 UI 上!
2. 點擊 START DETECTION 啟動 AI 語音分析引擎。
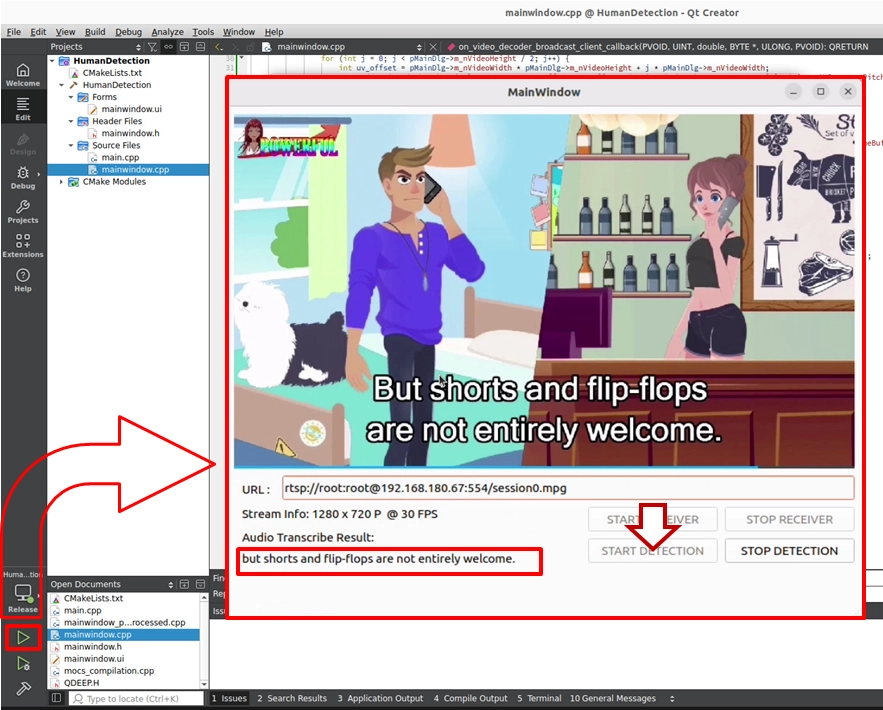
➤ 溫馨小叮嚀 ( 非常重要 ) : 在您第一次開啟軟體的瞬間,介面可能會需要稍等一下才會顯示。模型在首次執行時必須進行初始化配置,將龐大的神經網路權重與語音字典載入到 GPU 中。只要軟體成功開啟,代表 AI 大腦已經準備就緒!後續開啟就不需要這個等待時間了!
➤ 測試結果 : 當畫面中的人物開始說英文時,您將會看到非常流暢的轉錄體驗: 在軟體介面下方的 QLabel 區塊中,會即時顯示出「Audio Transcribe Result:」,並隨著人物的語句動態浮現出對應的英文字幕! 例如:當影片中的角色說出:"But shorts and flip-flops are not entirely welcome." ,介面下方就會完美捕捉並精準顯示這段原汁原味的英文對話!