10-15 英語音声テキスト変換機能サンプルチュートリアル
人型、多特徴、工安防災など、さまざまな「画像認識」機能を体験した後、本章では NexVDO SDK のもう一つの強力な可能性である「音声処理」を解放します。
ここでは、英語圏向けに訓練された音声テキスト変換モデルを導入します。これにより、ソフトウェアは画面を「理解する」だけでなく、音も「理解」できるようになり、受信したリアルタイム音声ストリームを瞬時に文字字幕へ変換できます。この技術は、多国籍ビデオ会議の記録、英語遠隔授業のリアルタイム字幕、動画の自動字幕生成などのスマートシーンに非常に適しています。
学習目標
本章を通して、以下を学びます。
1. 音声分析シーンに向けて、専用の英語音声テキスト変換モデルを設定し、読み込みます。
2. 「画像データストリーム」から「音声データストリーム」へ切り替える際の核心的なフローの違いを理解し、SDK 内蔵の仕組みを使って画面を直接レンダリングします。
3. プログラム内で専用の AI コールバック関数 (QDEEP_REGISTER_OBJECT_DETECT_CALLBACK) を登録し、音声認識結果を取得する方法を学びます。
4. UI インターフェースを拡張し、認識された文字をリアルタイムに更新して Qt のラベル(QLabel)上に表示します。
準備作業
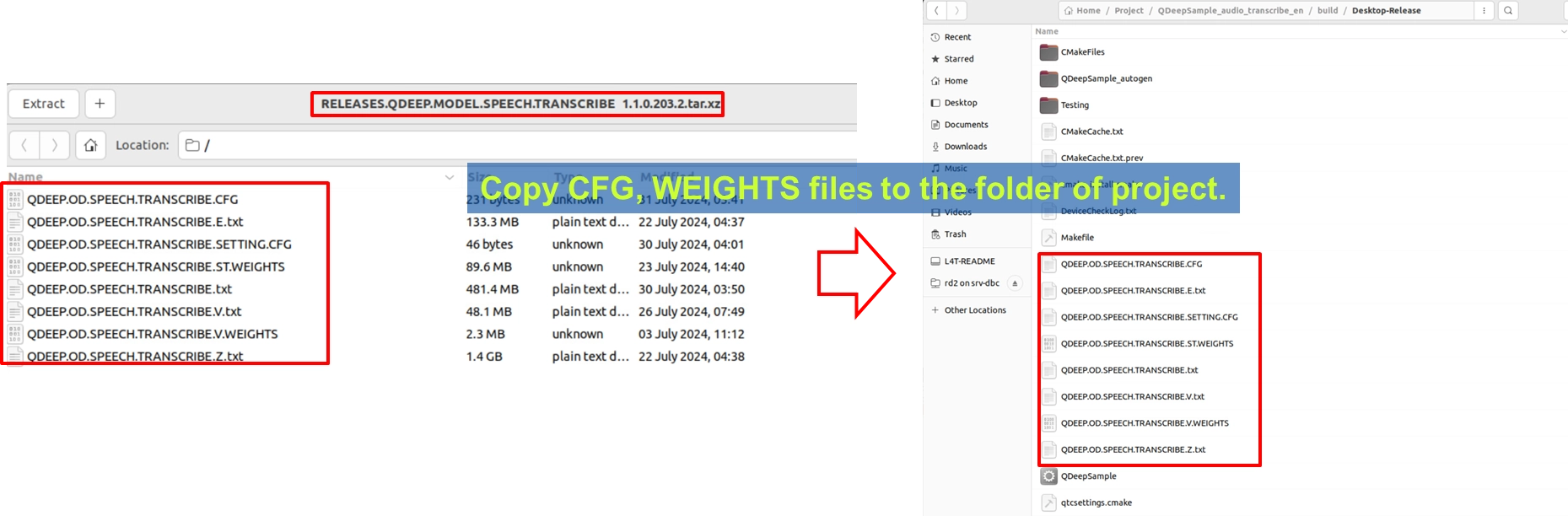
AI に英語の聞き取り能力を持たせるには、音声認識に特化した「頭脳」に切り替える必要があります。今回のモデルパッケージには、複数の設定ファイル、重みファイル、および関連するテキストファイルが含まれているため、ファイル数は比較的多くなります。
1. 音声テキスト変換モデルの圧縮ファイルを見つけてください。ファイル名には RELEASES.QDEEP.MODEL.SPEECH.TRANSCRIBE に関連する文字列が含まれている場合があります。
2. 解凍後、内部の QDEEP.OD.SPEECH.TRANSCRIBE.CFG (設定ファイル)、すべての対応する重みファイル (.WEIGHTS)、および辞書/テキストファイル (.txt, .SETTING.CFG) を、Qt プロジェクトの ビルド出力ディレクトリ (実行ファイルと同じ階層)へまとめてコピーしてください。
核心概念の解説:「画像」から「音声」へのフロー変換
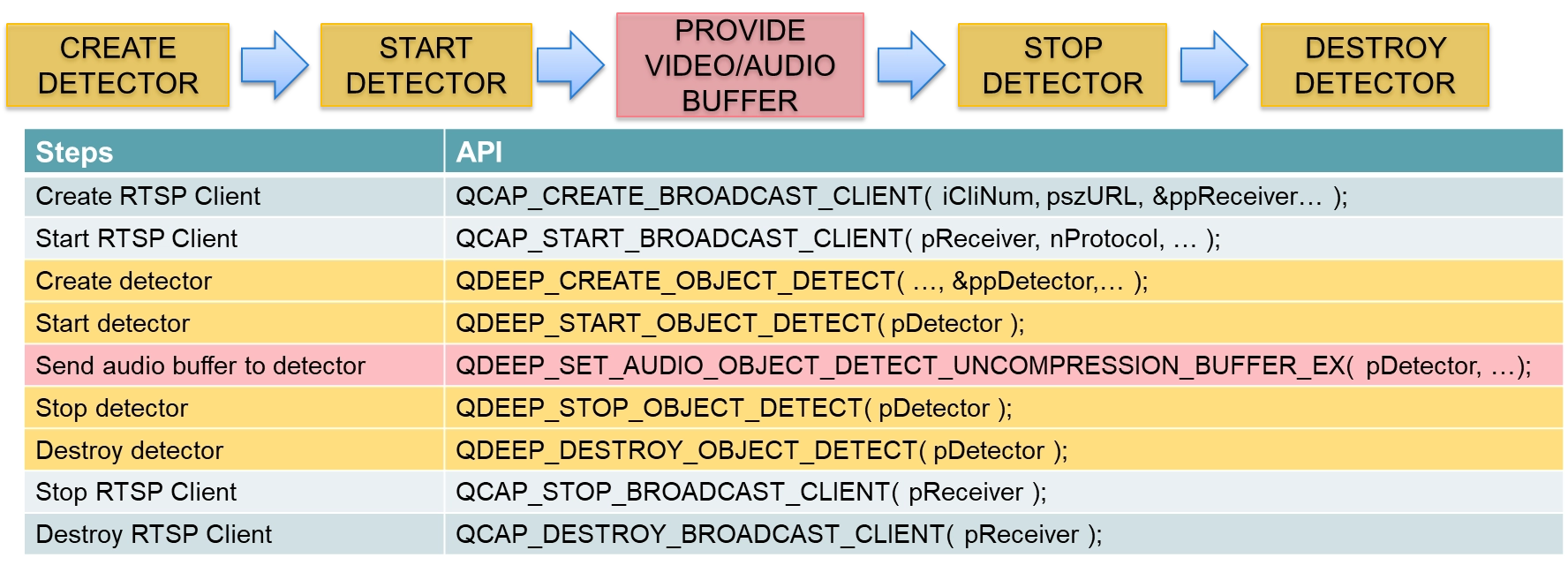
正式に API を変更する前に、非常に重要な核心概念を明確にしておく必要があります。これまで説明してきたのは画像処理でしたが、今回は音声処理です。
• これまでの画像フロー : on_video_decoder_broadcast_client_callback を通してデコード後の NV12 画像データをインターセプトし、 QDEEP_SET_VIDEO_OBJECT_DETECT_UNCOMPRESSION_BUFFER を呼び出して画面を AI に渡していました。
• 新しい音声フロー : モデルは音声を対象に認識を行うため、ユーザーは「音声データ」を検出器へ送信する必要があります。そのため、音声デコードの受信を担当する on_audio_decoder_broadcast_client_callback から、クリーンな PCM 音声データをインターセプトする必要があります。そして、音声専用に設計された新しい API (QDEEP_SET_AUDIO_...) を使って、これらの音声特徴を渡します。
➤ 受信側のオーディオコールバック関数については、こちらを振り返ることができます : 10-9 RTSP ストリーム受信側(クライアント)機能の実践チュートリアル
コア API はどのように変更するのか
フローの違いを理解したところで、変更および追加が必要なコア API を見てみましょう。
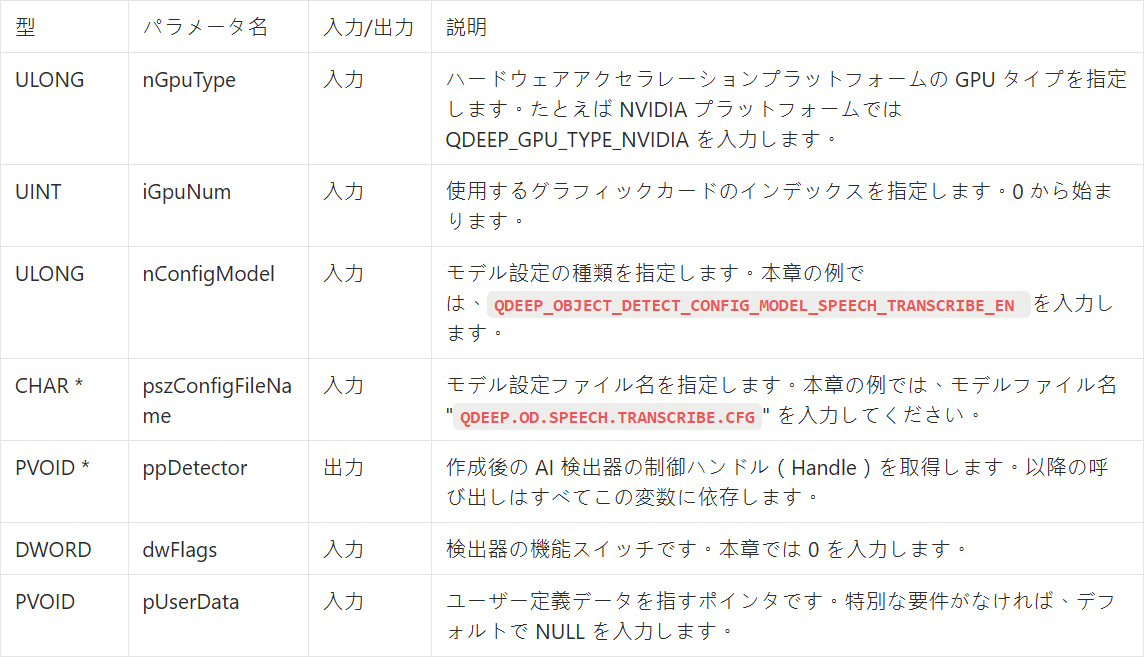
• モデル設定 Enum の変更 : QDEEP_CREATE_OBJECT_DETECT で、専用の QDEEP_OBJECT_DETECT_CONFIG_MODEL_SPEECH_TRANSCRIBE_ENに変更してください。
• 音声認識結果の登録 : QDEEP_REGISTER_OBJECT_DETECT_CALLBACKを通して認識結果を取得する必要があります。
QDEEP_CREATE_OBJECT_DETECT
これは AI エンジンを作成し、「頭脳」(モデル)を読み込むための最も重要な API です。ユーザーはこの API を通して検出器を初期化する必要があります。
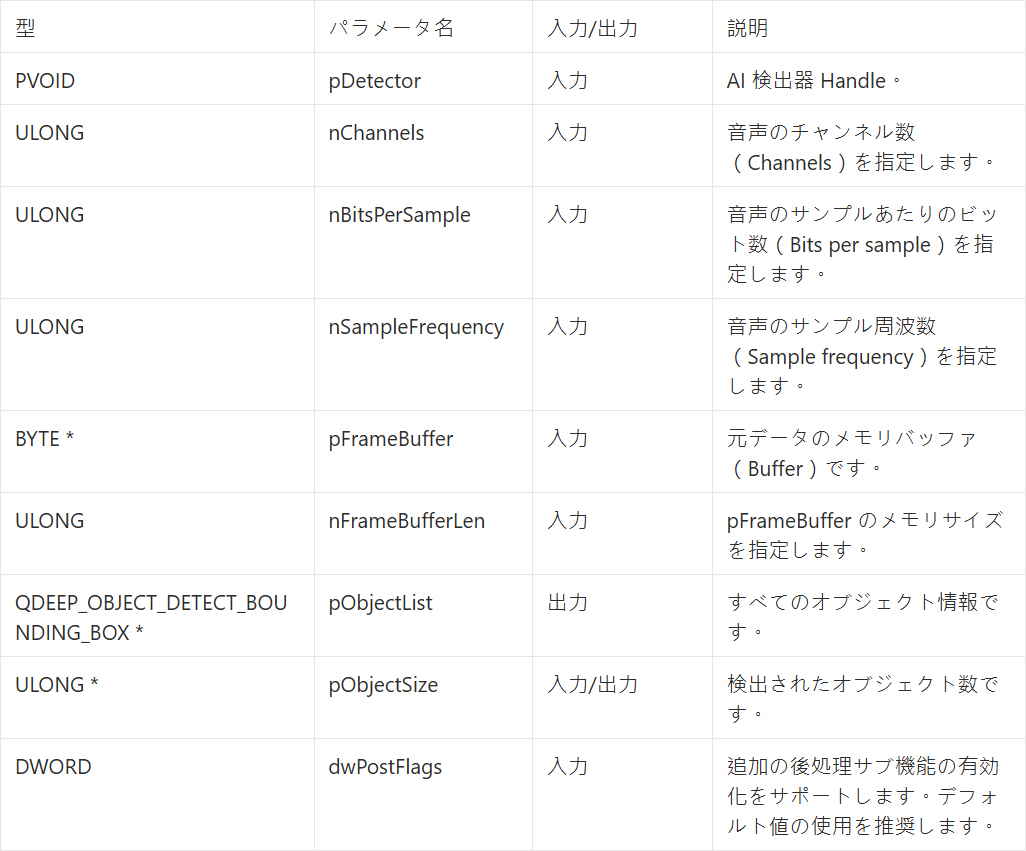
QDEEP_SET_AUDIO_OBJECT_DETECT_UNCOMPRESSION_BUFFER_EX
この API は on_audio_decoder_broadcast_client_callback の中で呼び出し、音声データを継続的に AI 検出器へ提供します。画像と比べて、音声では異なる物理パラメータを渡す必要があります。
データコールバック:音声認識結果の取得
• Registration API : QDEEP_REGISTER_OBJECT_DETECT_CALLBACK
• トリガータイミング : AI エンジンが一文を聞き終えて認識を完了すると、この Callback を通して英語の文を能動的に渡してきます。
• 返される情報パラメータ (PF_OBJECT_DETECT_CALLBACK) :
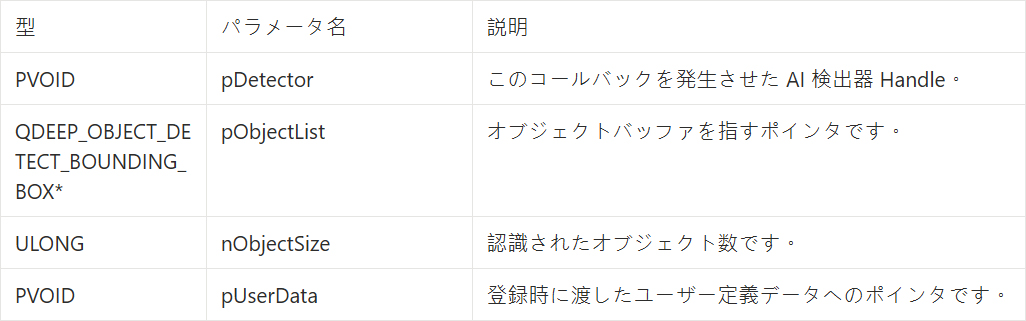
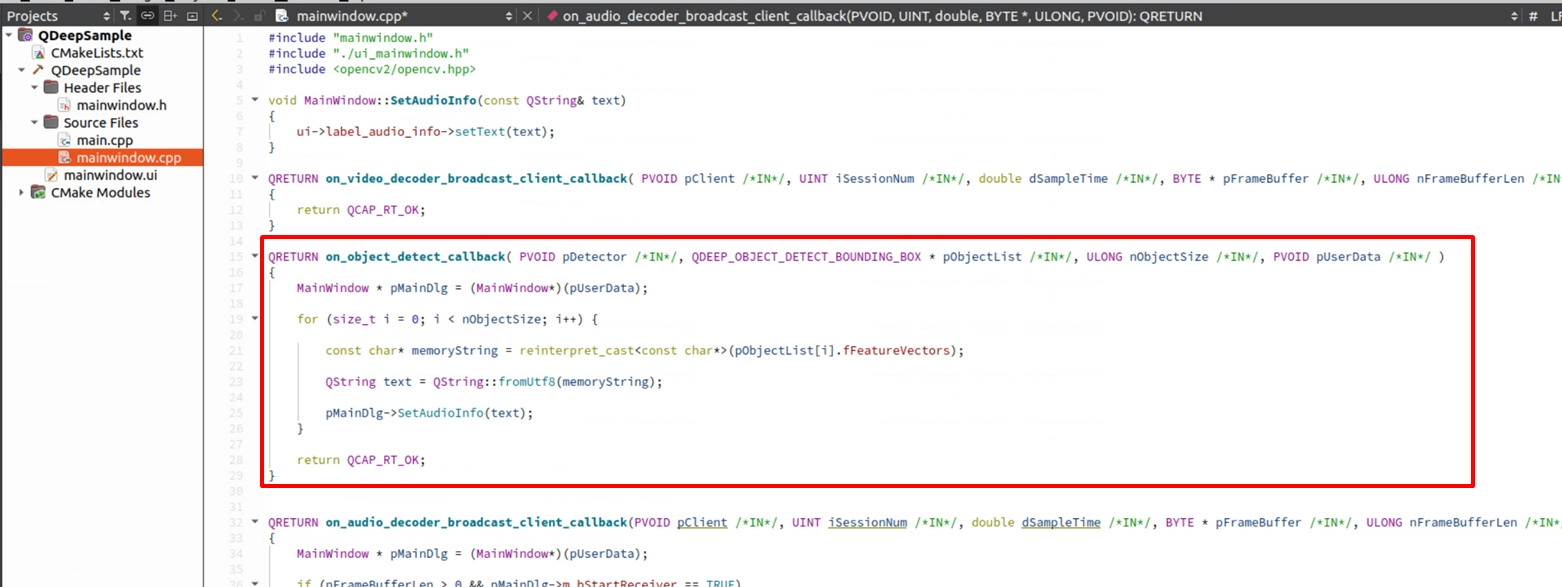
QDEEP_OBJECT_DETECT_BOUNDING_BOX 構造体
音声テキスト変換モデルでは、SDK はこのフィールドを通して音声認識結果に関連するデータを出力します。AI エンジンは、この構造体内の fFeatureVectors パラメータを通して、音声認識結果を私たちが取得できるようにします。

コアコードの作成
プロジェクトを開き、重要な微調整を行います。
字幕表示インターフェース(QLabel)の追加
今回の結果は「テキスト字幕」であるため、mainwindow.uiを開き、画面の下部に QLabel コンポーネントを追加して、 label_audio_info という名前を付けてください。これは音声認識の英語の結果を専用に表示するためのものです。
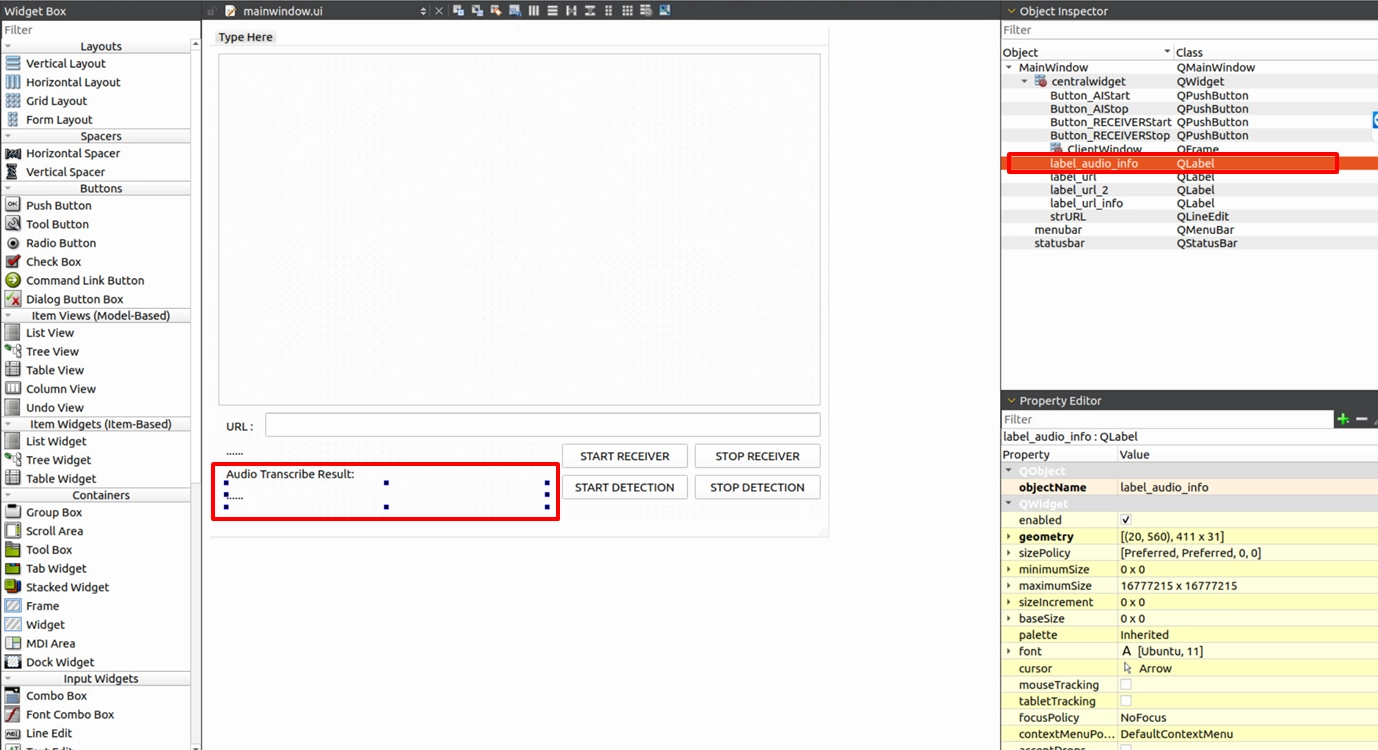
次に、グローバルな Callback が安全に UI を変更できるように、 mainwindow.h 内でパブリックな専用関数を宣言する必要があります:
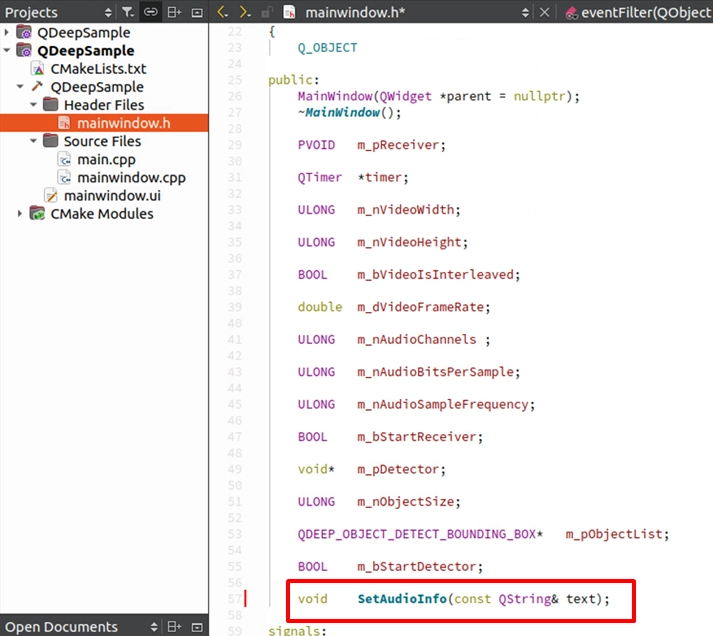
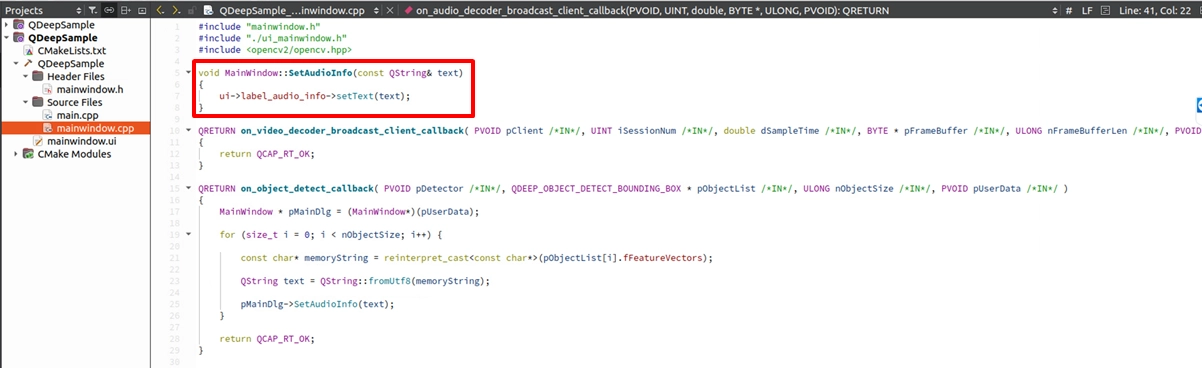
そして、それを mainwindow.cpp で実装します。ロジックは非常にシンプルで、受信した文字列をラベルに設定するだけです:
SDK ネイティブ画面レンダリングのバインド
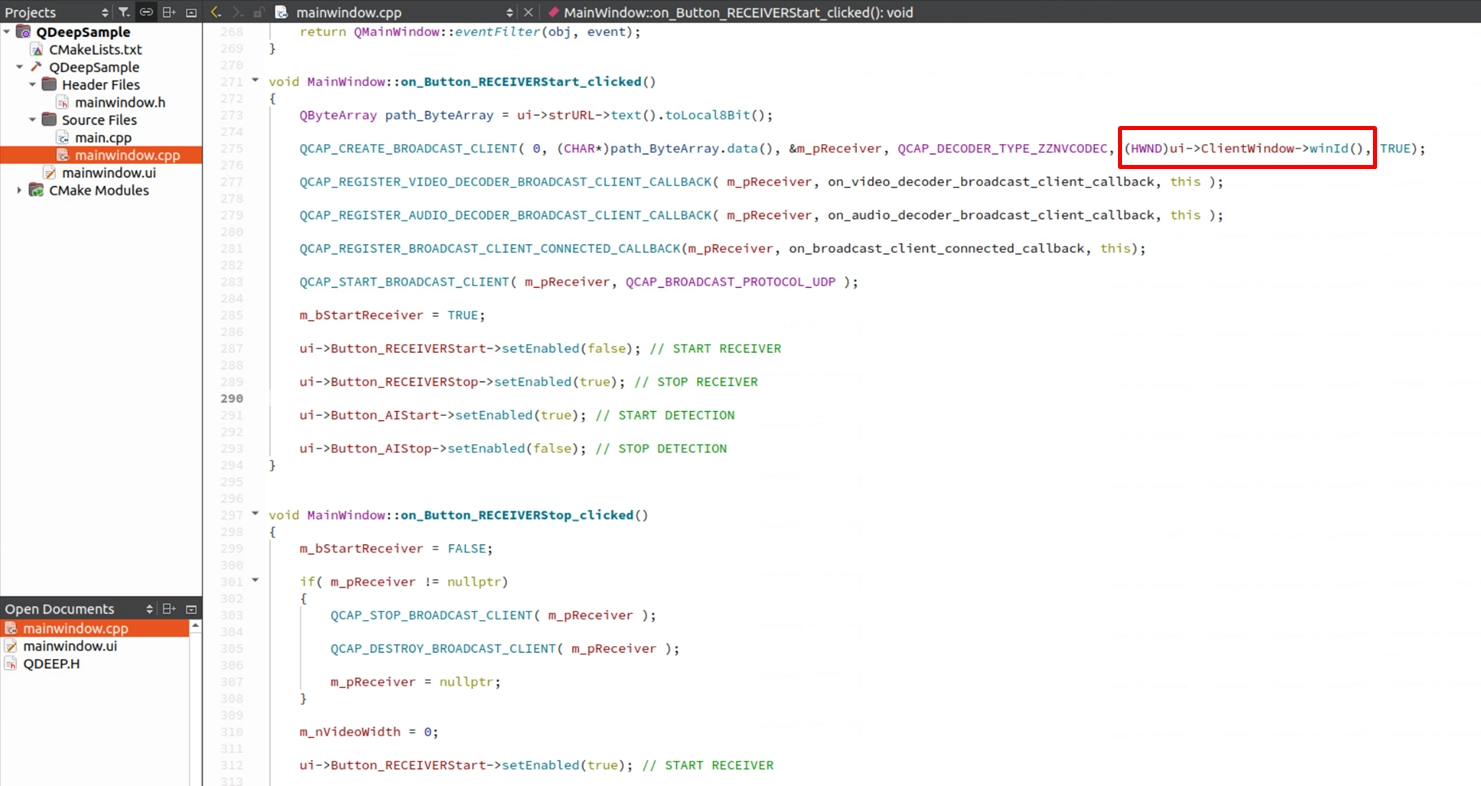
前の章では、画面上に AI 追跡枠を描画するために、元画像をインターセプトし、手間をかけて OpenCV 形式 (cv::Mat) へ変換し、さらに QPainter で描画する必要がありました。しかし本章では、 「音声」だけを対象に認識を行い、映像部分は加工する必要がない ため、RTSP Client API のネイティブ機能を直接利用できます。UI の表示ウィンドウを SDK にバインドし、自動的に画面を再生させることで、コードを大幅に簡略化できます。
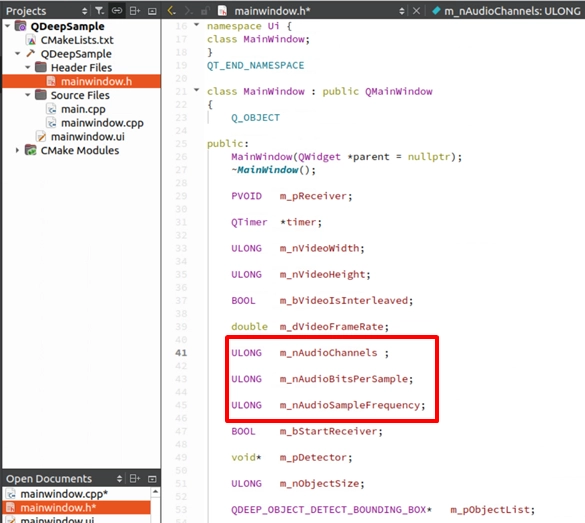
音声情報変数の宣言
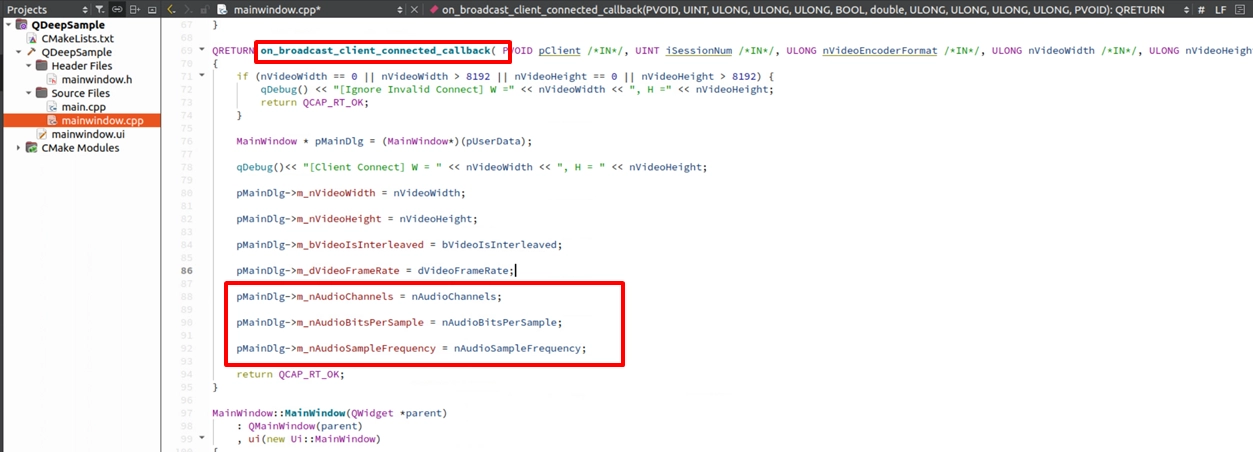
モデル読み込みと Callback 登録

Audio Callback 内で音声を渡す
on_audio_decoder_broadcast_client_callback 関数を見つけてください。 QDEEP_SET_AUDIO_OBJECT_DETECT_UNCOMPRESSION_BUFFER_EX を使い、インターセプトした PCM 音声データ (pFrameBuffer) 、チャンネル数、サンプリングレートなどのパラメータを AI エンジンへ渡します。その後、専用のコールバック関数内で音声認識結果を取得し、結果を表示するために QLabel に渡します。ただし、AI 機能が有効になっていない場合、label_audio_info はデフォルトの文字列を表示します。
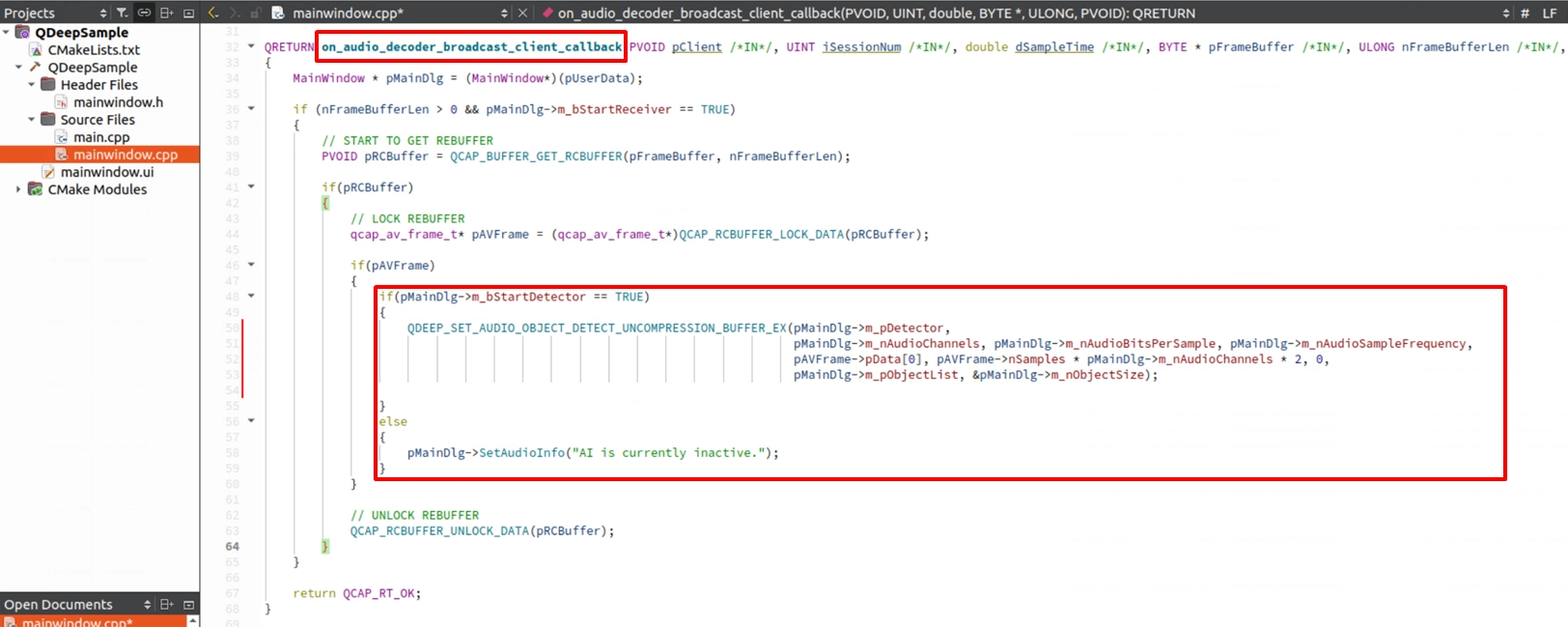
Callback 内で認識結果を取り出し、QLabel を更新する
最終確認
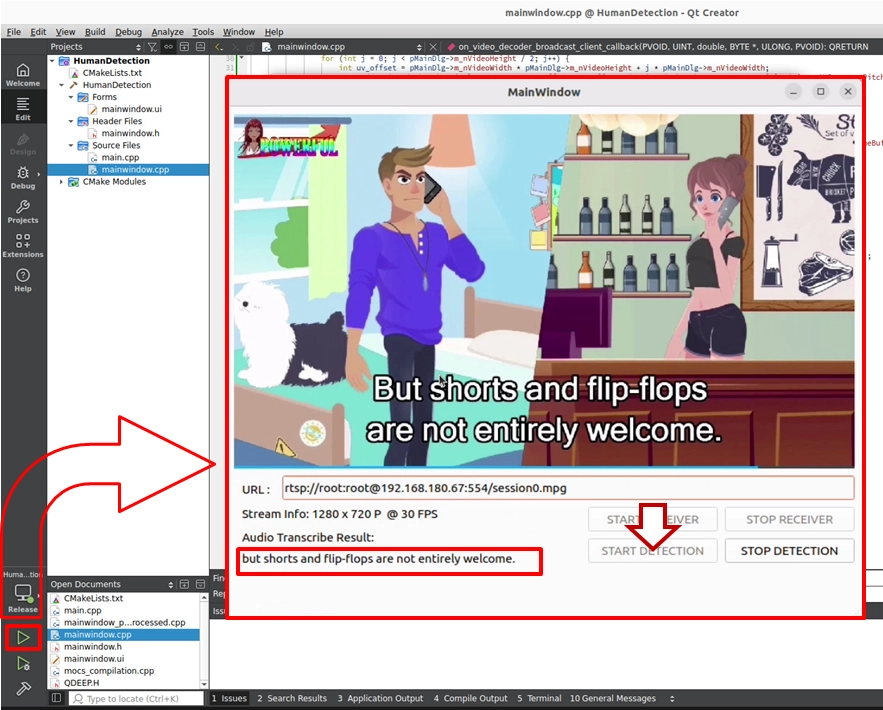
初めての AI 英語ディクテーションアシスタントを迎える準備はできましたか。では、左下の 「Build and RUN」 をクリックしてプロジェクトを実行してください。
1. 「英語の人声」が含まれる音声トラック付き動画の RTSP URL を入力し、 START RECEIVER to をクリックしてストリームの受信を開始します。この時点で、画面は SDK によって自動的かつスムーズに UI 上へ直接描画されます。
2. START DETECTION をクリックし、AI 音声分析エンジンを起動します。
➤ 補足リマインダー(非常に重要) : 初めてソフトウェアを起動する瞬間、インターフェースが表示されるまで少し時間がかかる場合があります。初回実行時にはモデルの初期化設定が必要であり、巨大なニューラルネットワークの重みと音声辞書を GPU に読み込む必要があります。ソフトウェアが正常に起動すれば、AI の頭脳は準備完了です。以降の起動では、この待ち時間は不要になります。
➤ テスト結果 : 画面内の人物が英語を話し始めると、非常にスムーズな文字起こし体験を確認できます。ソフトウェア画面下部の QLabel 領域には、「Audio Transcribe Result:」がリアルタイムで表示され、人物の発話に合わせて対応する英語字幕が動的に表示されます。たとえば、動画内の人物が "But shorts and flip-flops are not entirely welcome." と話すと、画面下部ではその自然な英語会話が正確にキャプチャされ、表示されます。