10-1 NexVDO SDK - QDEEP 功能概覽與架構
還記得我們在 9-1 NexVDO SDK - QCAP 功能概覽與架構章節 中,初次見面的那張「 NexVDO SDK 方塊圖 」嗎?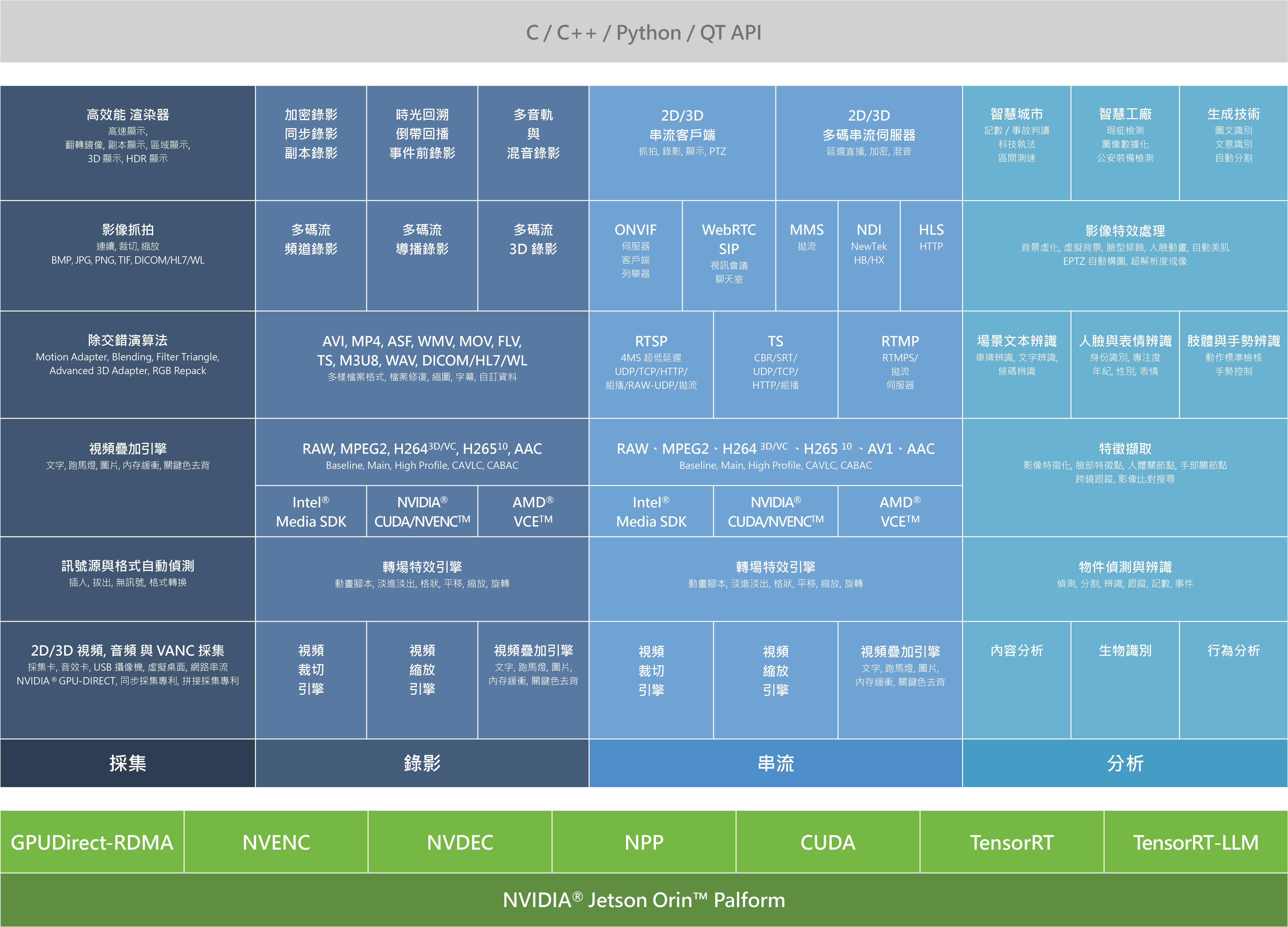
➤ 官方參考資訊 若想一睹為快這套 SDK 的完整規格與產品細節,歡迎先行前往 聰泰官方產品頁面 了解更多!
回顧這段時間的實戰演練,我們已經成功征服了方塊圖的前三大領域,也就是由 QCAP 所負責的:採集 ( Capture )、錄影 ( Record ) 以及 串流 ( Stream )。我們學會了如何高效率地把攝影機畫面抓進電腦,如何將它們壓縮成 MP4 檔案,甚至是如何把它們推播到 YouTube 上與全世界分享。
然而,在現今的科技趨勢中,光是「看見」與「傳遞」影像已經不夠了。為了讓傳統產業升級,我們需要讓電腦擁有「大腦」,也就是讓軟體具備看懂畫面內容的 AI 人工智慧。
今天,我們終於要解鎖方塊圖中最具含金量的最後一塊核心領域——分析 ( Analysis ),並正式向您介紹 NexVDO SDK 中的 AI 大腦 :QDEEP 引擎!
分析
NexVDO SDK 的 QDEEP 引擎完美整合了 NVIDIA 與 Intel 的 GPU 加速技術,大幅提升了深度學習 ( Deep Learning ) 推論的效率。它將 AI 分析功能劃分為以下三大核心模組,幾乎涵蓋了市面上所有的應用場景 :
三大基礎分析模組
這個模組旨在讓電腦「理解」畫面中的特定物件與事件。
1. 內容分析:讓電腦看懂畫面中的脈絡。
• 物件偵測與辨識 : 涵蓋了偵測、分割、辨識、跟蹤、統計,直到最終的事件觸發。
• 場景文本辨識 : 支援車牌辨識、文字辨識與條碼辨識,能快速將畫面中的關鍵資訊數位化。
2. 生物識別 :深入解析人體的特徵資訊。
• 特徵擷取 :將影像特徵化,精準抓取臉部特徵點、人體關節點、手部關節點,甚至支援跨鏡跟蹤與影像 / 聲音比對搜尋。
• 人臉與表情辨識 : 不僅支援身份識別,還能量化出對象的專注度、年紀、性別與表情。
3. 行為分析 :針對連續動態影像的進階應用。
• 肢體與手勢辨識 :可用來進行動作標準檢核以及直覺的手勢控制。
AI 影像特效處理
這是一個將 AI 與傳統影音完美結合的亮點模組。透過神經網路的輔助,QDEEP 能做到廣電與視訊會議等級的影像特效處理,包含 :
• 背景虛化與虛擬背景( 去背 )
• EPTZ 自動構圖( 讓鏡頭永遠跟著主角 )
• 人物透明化( 例如 : 在遠距教學或課程錄影時,當講師站在黑板前寫字,AI 能即時識別並將講師的身軀透明化,如此一來,觀眾的視線就完全不會被遮蔽,能毫無死角地看清楚黑板上的完整字跡 )
頂層的垂直應用與次世代技術
在架構圖的最頂端,QDEEP 引擎完美跨越了傳統純視覺的界線,融合了最先進的生成式 AI 與大語言模型,將底層的數據昇華為具備「 邏輯思考與對話能力 」的三大引擎 :
• 智慧語音引擎 :讓系統不只是「 看 」,還能「 聽 」與「 說 」。它支援多語系即時字幕生成,並能以擬真語音播報將系統訊息傳達給使用者。更強大的是,它允許開發者打造語音指令驅動的軟體介面,讓使用者能直接用語音控制系統。
• 智慧影音推理 :賦予電腦真正的「 邏輯思考 」能力。它能看懂複雜的畫面脈絡並提供真實場景危險預警;面對長達數十小時的監控錄影檔,它能快速進行長影音事件解析。更令人驚豔的是,它支援自然語言搜圖——您只需輸入「 找出穿紅衣服、戴帽子的男子 」,系統就能自動理解語意,從茫茫影像中精準撈出目標畫面!
• 智慧對話代理 :它具備強大的內容自動總結能力,能看懂影像與數據並自動生成報告。同時內建了 24 HR 問答客服與多國語言即時翻譯,完美勝任智慧無人櫃台。
( 當然,除了這三大引擎,這一層也同時包含了能直接落地的智慧交通與智慧工廠等垂直產業解決方案,以及強大的生成技術,為開發者提供全方位的奧援。)
準備好進入實戰了嗎?
透過上述的介紹,我們可以清楚看到,無論是 QCAP 還是 QDEEP,NexVDO SDK 的最終目的,就是幫開發者把底層最骯髒、最耗效能的泥沼給鋪平。從影像採集一直到智慧分析,它為我們提供了一條不可思議的加速捷徑!
俗話說「 工欲善其事,必先利其器 」。在我們正式召喚各種強大的 AI 模型( 例如 : 辨識人形、人臉、車輛或物件等 )之前,我們需要一個穩健的「 專案地基 」。
回想一下我們剛剛看過的架構圖,所有的 AI 影像分析其實都有一套標準的運作 S.O.P :「 接收影像串流 ➔ 畫面解碼 ➔ 送入 AI 引擎 ➔ 用 OpenCV 畫出辨識框 」。
➤ 在這裡要特別向大家說明一個重要觀念 :透過 NexVDO SDK 強大的 QCAP 模組,獲取「 影像數據 」的方式是非常多元的!您可以從實體的影像擷取卡 ( HDMI / SDI )、本地影音檔案,或者是網路串流中取得畫面。為了教學的方便性與統一性,我們接下來的 AI 系列範例,都將以 「 接收 RTSP 影像串流 」 作為影像輸入源的示範代表。
為了避免在未來的每一個 AI 功能實作中,都要重複經歷拉 UI、設定 CMake 依賴庫以及撰寫網路連線的繁瑣過程,在 下一章 【10-2】 打造 AI 視覺分析基礎樣板專案 中,我們將帶著您先把這套「 標準流程 」寫成一個萬用的開發框架( QDeepSample )。
這個乾淨的樣板將會成為您未來開發所有智慧視覺應用的最強基底!只要打好這個地基,之後在未來的章節中,無論您想換上哪一種 AI 模型,都只需要「 替換模型檔案 」與「 修改幾行核心 API 」,就能瞬間賦予程式全新的視覺辨識能力。
打開您的 Qt Creator,準備好大展身手了嗎 ?我們下一章見 !