10-1 NexVDO SDK - QDEEP 機能の概要とアーキテクチャ
9-1 NexVDO SDK - QCAP 機能の概要とアーキテクチャ の章で初めて目にした「NexVDO SDK ブロック図」を覚えていますか?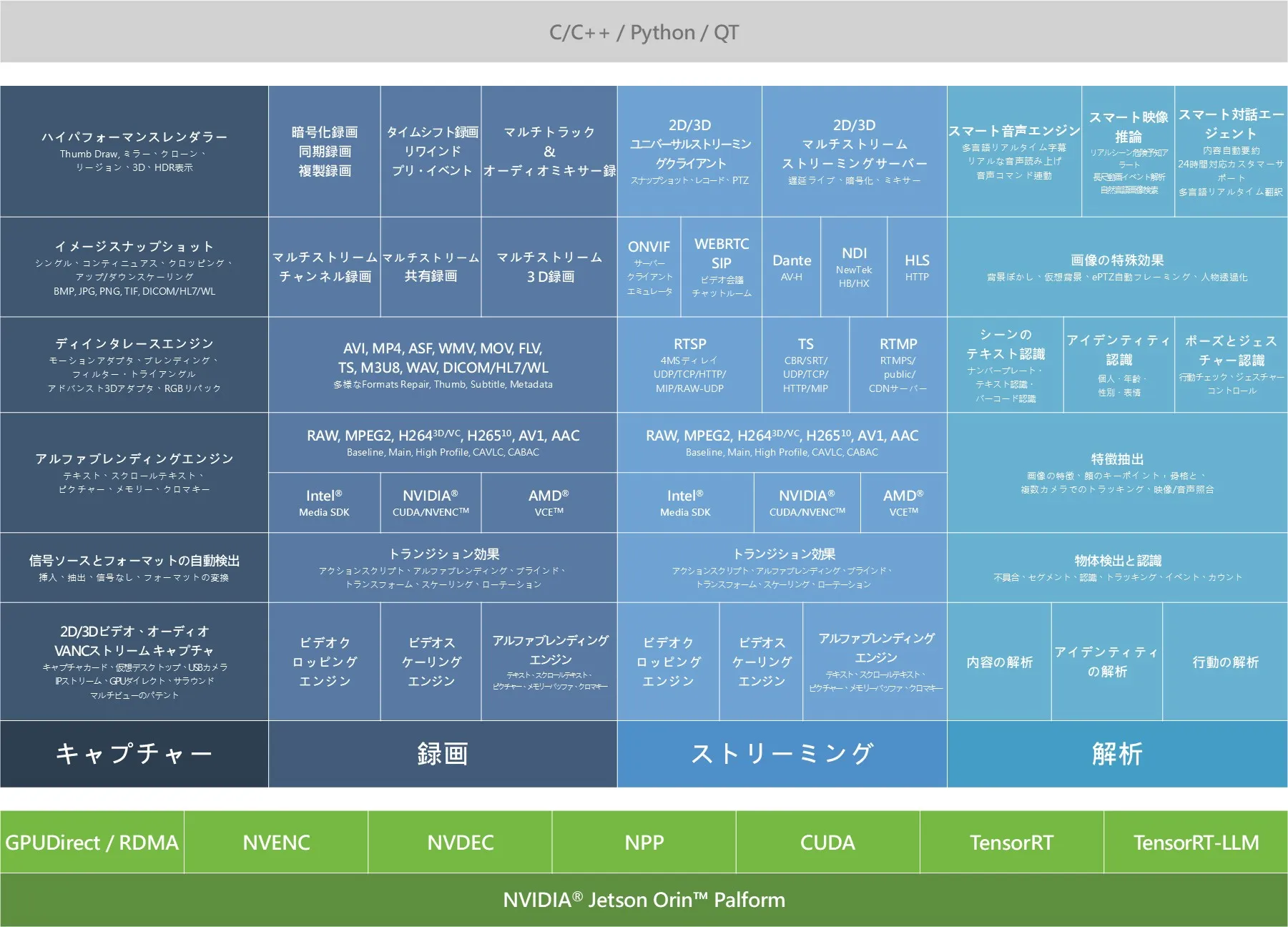
➤ 公式参考情報: このSDKの完全な仕様と製品の詳細をいち早く確認したい場合は、ぜひ先に YUAN公式製品ページ にアクセスして詳細をご覧ください!
これまでの実践演習を振り返ると、ブロック図の最初の3つの主要領域、つまり QCAP が担当する キャプチャ ( Capture )、録画 ( Record )、ストリーミング ( Stream ) を無事にマスターしました。カメラの映像を効率的にコンピューターに取り込む方法や、それらをMP4ファイルに圧縮する方法、さらにはYouTubeに配信して世界中と共有する方法を学びました。
しかし、現在のテクノロジートレンドにおいて、映像を単に「 見る 」「 伝える 」だけではもはや十分ではありません。伝統的な産業をアップグレードするためには、コンピューターに「 頭脳 」を持たせる必要があります。つまり、ソフトウェアに映像の内容を理解できる AI( 人工知能 )を備えさせる必要があるのです。
今日、私たちはついにブロック図の中で最も価値のある最後のコア領域である 分析 ( Analysis ) を解放し、NexVDO SDK の AI 頭脳である QDEEP エンジン を正式にご紹介します!
分析
NexVDO SDK の QDEEP エンジンは、NVIDIA と Intel の GPU アクセラレーション技術を完璧に統合し、ディープラーニング ( Deep Learning ) 推論の効率を大幅に向上させています。AI 分析機能を以下の3つのコアモジュールに分割しており、市場のほぼすべてのアプリケーションシナリオを網羅しています :
3つの基礎分析モジュール
このモジュールは、コンピューターに画面内の特定のオブジェクトやイベントを「 理解 」させることを目的としています。
1. コンテンツ分析 ( Content Analysis ) : コンピューターに画面内のコンテキストを理解させます。
• オブジェクト検出と認識 : 検出、セグメンテーション、認識、トラッキング、カウントから、最終的なイベントのトリガーまでをカバーします。
• シーンテキスト認識 : ナンバープレート認識 ( LPR )、文字認識 ( OCR )、バーコード認識をサポートし、画面内の重要な情報を迅速にデジタル化します。
2. 生体認証 ( Biometric Analysis ) : 人体の特徴情報を深く解析します。
• 特徴抽出 : 映像を特徴化し、顔の特徴点、人体の関節点、手の関節点を正確にキャプチャします。さらに、カメラ間のトラッキングや画像/音声の照合検索もサポートします。
• 顔と表情の認識 : 身元確認をサポートするだけでなく、対象者の集中度、年齢、性別、表情を定量化することができます。
3. 行動分析 ( Behavior Analysis ) : 連続する動的映像に対する高度なアプリケーションです。
• 姿勢とジェスチャー認識 : 動作の標準チェックや直感的なジェスチャーコントロールに使用できます。
AI 映像エフェクト処理
これは、AI と従来のオーディオ・ビデオを完璧に融合させたハイライトモジュールです。ニューラルネットワークの支援により、QDEEP は放送やビデオ会議レベルの映像エフェクト処理を実現できます。これには以下が含まれます。
• 背景ぼかしと仮想背景( 背景の除去 )
• EPTZ 自動フレーミング( カメラが常に被写体を追従 )
• 人物透過( 例えば、遠隔授業や授業の録画で、講師が黒板の前に立って文字を書いている場合、AI は即座に認識し、講師の体を透過させることができます。これにより、視聴者の視線が遮られることなく、黒板の文字全体を死角なしで明確に見ることができます。)
最上位の垂直アプリケーションと次世代テクノロジー
アーキテクチャ図の最上位において、QDEEP エンジンは従来の純粋なビジョンの境界を完璧に越え、最先端の生成 AI ( Generative AI ) と大規模言語モデル ( LLM ) を統合し、基礎となるデータを「 論理的思考と対話能力 」を備えた3つの主要エンジンへと昇華させます。
• スマート音声エンジン : システムに「 見る 」だけでなく「 聞く 」「 話す 」ことを可能にします。多言語のリアルタイム字幕生成をサポートし、リアルな音声放送でシステムメッセージをユーザーに伝えることができます。さらに強力なことに、開発者が音声コマンド駆動のソフトウェアインターフェースを構築できるようにし、ユーザーが音声で直接システムを制御できるようにします。
• スマート映像推論 : コンピューターに真の「 論理的思考 」能力を与えます。複雑な画面のコンテキストを理解し、実際のシーンでの危険警告を提供できます。数十時間にも及ぶ監視録画ファイルに直面しても、長時間の映像イベント解析を迅速に実行できます。さらに驚くべきことに、自然言語による画像検索をサポートしています。例えば、「 赤い服を着て帽子を被った男を見つけて 」と入力するだけで、システムは自動的に意味を理解し、膨大な映像の中からターゲット画面を正確に抽出できます!
• スマート対話エージェント : 強力なコンテンツの自動要約機能を備えており、映像とデータを理解してレポートを自動生成できます。また、24時間対応の Q&A カスタマーサービスと多言語リアルタイム翻訳を内蔵しており、スマートな無人受付の役割を完璧にこなします。
(もちろん、これら3つの主要エンジンに加えて、このレイヤーにはスマート交通やスマートファクトリーなどの直接導入可能な垂直産業ソリューション、および強力な生成テクノロジーも含まれており、開発者に包括的なサポートを提供します。)
実践に入る準備はできましたか?
上記の紹介から、QCAPであれQDEEPであれ、NexVDO SDKの最終的な目的は、開発者のために最も煩雑でパフォーマンスを消費する低レイヤーの泥沼を平坦にすることであることがはっきりと分かります。映像キャプチャからインテリジェント分析に至るまで、それは私たちに信じられないほどの加速ショートカットを提供してくれます!
「 良い仕事をするには、まず道具を研ぐ必要がある」という諺があるように、様々な強力なAIモデル( 例えば、人物、顔、車両、またはオブジェクトの認識など )を正式に呼び出す前に、確固たる「 プロジェクトの基盤 」が必要です。
先ほど見たアーキテクチャ図を思い返してみてください。すべてのAI映像分析には、実は標準的なS.O.P(標準作業手順)が存在します :「 映像ストリームの受信 ➔ 画面のデコード ➔ AIエンジンへの送信 ➔ OpenCVを使用した認識枠の描画 」です。
➤ ここで特に皆様に説明しておきたい重要な概念があります:NexVDO SDKの強力な QCAP モジュール を通じて、「 映像データ 」を取得する方法は非常に多様です!物理的なビデオキャプチャカード( HDMI / SDI )、ローカルの動画ファイル、またはネットワークストリームから画面を取得することができます。教育の利便性と統一性のために、今後のAIシリーズのサンプルでは、すべて「 RTSP映像ストリームの受信 」を映像入力ソースの代表例として使用します。
将来のすべてのAI機能の実装において、UIの作成、CMake依存ライブラリの設定、およびネットワーク接続コードの記述という煩雑なプロセスを繰り返すのを避けるため、次の章 【10-2】AIビジュアル分析の基礎テンプレートプロジェクトの構築 では、まずこの「標準プロセス」を汎用的な開発フレームワーク( QDeepSample )として書き上げるようご案内します。
このクリーンなテンプレートは、将来すべてのスマートビジュアルアプリケーションを開発するための最強の基盤となります!この基盤さえしっかり固めておけば、今後の章でどのAIモデルに切り替えたい場合でも、「 モデルファイルの置き換え 」と「 数行のコアAPIの変更 」を行うだけで、プログラムに全く新しい視覚認識能力を瞬時に与えることができます。
Qt Creatorを開いて、腕を振るう準備はできましたか?それでは、次の章でお会いしましょう!