10-14 智慧板書提取功能範例教學
在過去的 【10-12】與【10-13】章節中,我們完美掌握了「背景模糊」與「虛擬背景替換」的技術。在那些應用中,AI 的核心任務是:「把人物保留下來,並把背景處理掉」。
但現在,請想像一個極度常見的教育場景:您正在觀看一段線上課程的錄影,講師在黑板上寫下了密密麻麻的精華公式,但他講得太激動了,身體一直擋住黑板上的字跡 ( Board Handwriting ),讓您根本無法抄寫筆記! 這時候,我們能不能讓 AI 反過來運作:把背景 ( 板書 ) 保留下來,把人物給『摳除』掉呢?
歡迎來到智慧教育領域的神奇技術——人物摳除與板書提取! 本章節我們將利用 NexVDO SDK 強大的背景建模能力,讓畫面中的講師宛如披上「隱形斗篷」,只留下他身後的完美板書。更棒的是,您將體會到這套 SDK 在底層架構上的極致共用性!
學習目標
透過本章節,您將學會 :
1. 思維反轉與模型重用 : 體會從「去背」到「去人」的邏輯轉換,並驚喜地發現我們竟能 沿用同一個 AI 模型檔案!
2. 掌握透明度門檻 API : 使用 Custom API 屬性,精準控制人物摳除的靈敏度與乾淨程度。
3. OpenCV 畫面並排對比 : 實作 cv::hconcat 函數,打造出「左邊原圖 vs 右邊板書提取」的專業級監控介面。
➤ 畫面並排對比構圖方式 :可以回顧 10-7 Human EPTZ Automatic Framing Sample Tutorial
準備工作
完全不用換模型檔案! 因為「去背」和「去人」在 AI 的底層原理上,都是必須精準切割出「人物輪廓」。因此這兩個功能共用了同一個權重檔! 請確認您的專案目錄下,依然放著我們前兩章用過的 QDEEP.OD.SEGMENTATION.PERSON.LIGHT.CFG 與其權重檔即可。
核心 API 要怎麼改?
雖然模型檔案相同,但我們必須在程式碼中給予 AI 不同的「配置 Enum」與「Custom API 屬性」,告訴它我們這次的任務是去除人物。
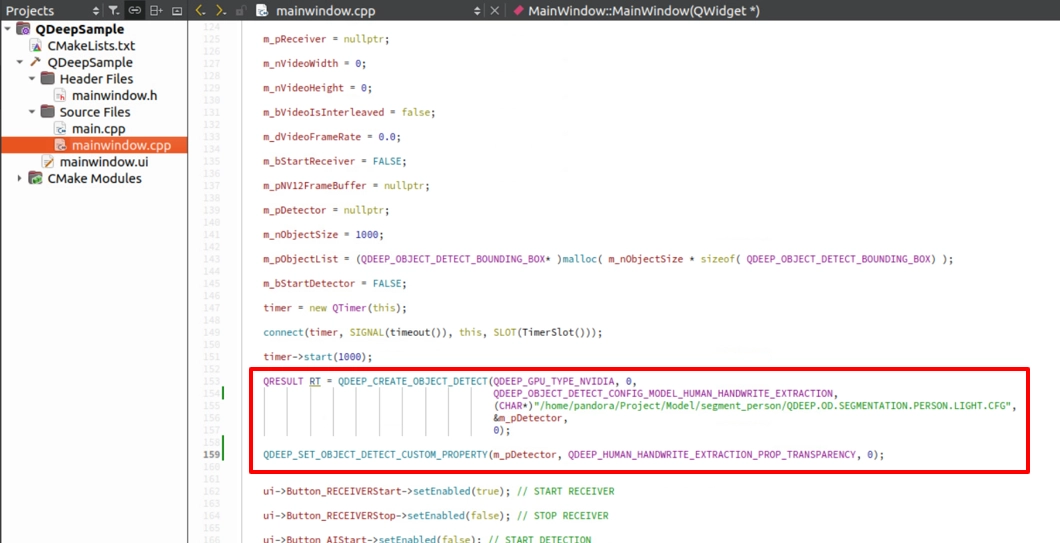
• 模型配置 Enum 的改變 : 在 QDEEP_CREATE_OBJECT_DETECT 中,請換成板書提取專屬的 QDEEP_OBJECT_DETECT_CONFIG_MODEL_HUMAN_HANDWRITE_EXTRACTION。
• 使用全新屬性控制「摳除靈敏度」 : 我們需要透過 QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY 傳入一個新的參數,來決定 AI 把人摳除得有多「徹底」。
QDEEP_CREATE_OBJECT_DETECT
這是建立 AI 引擎並載入大腦(模型)的最關鍵 API。使用者必須透過此 API 初始化偵測器。

QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY
我們使用 QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY 傳入一個 0~100 的 float 來控制人物遮罩的分割精細程度:

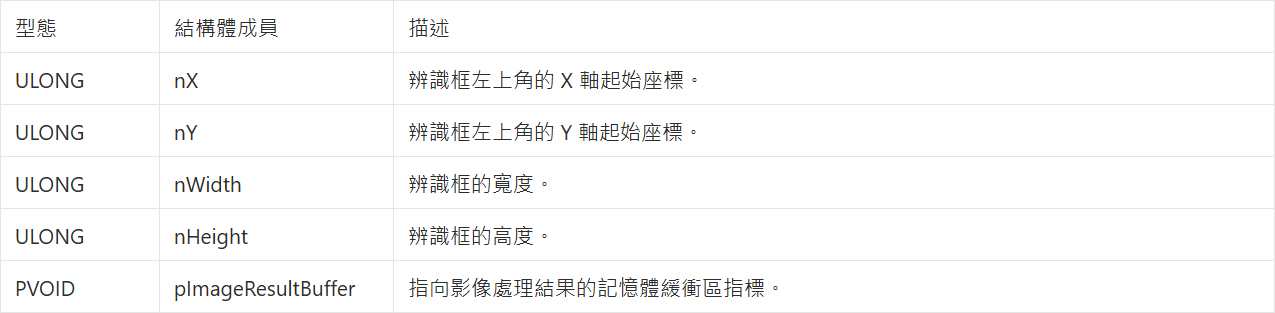
QDEEP_OBJECT_DETECT_BOUNDING_BOX 結構體
AI 引擎會在這個結構體中透過 pImageResultBuffer 參數將算好的高畫質影像像素(BGR格式)直接倒進這塊記憶體中供我們提取!
撰寫核心程式碼
請開啟您的專案,我們將進行關鍵的微調:
模型載入與設定靈敏度
在建構子中,套用我們剛剛介紹的新 Enum,並將摳除靈敏度直接設為最精確的 0:
沿用 10-12 的 ImageBuffer 處理架構
由於底層同樣是產出一張處理好的 BGR 高畫質圖片,我們完全不需要修改連線成功時的 Buffer 宣告。
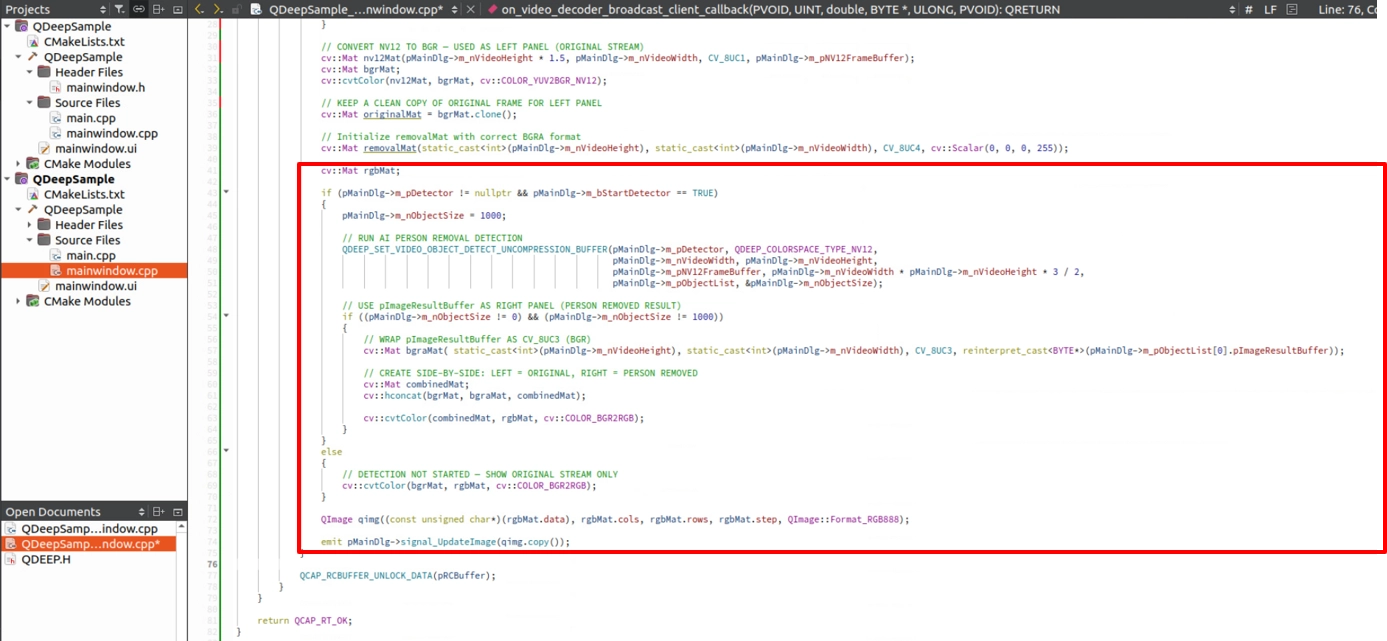
實作 OpenCV 左右並排對比
為了讓客戶一眼看出這項「隱形魔法」的強大,我們不應該直接蓋掉原圖,而是要把「原始影像」放左邊、「摳除人物後的影像」放右邊。還記得我們實作 10-7 人形 EPTZ 自動構圖時,為了同時監控「原圖」與「追蹤特寫」,所使用的那個 OpenCV 左右拼接神技嗎?我們在這裡不僅要重用它,還要加入一個設計: 當使用者還沒按下 START DETECTION 時,畫面應該單純只顯示寬廣的原始畫面;只有當 AI 啟動時,畫面才瞬間分割成左右對比!
➤ 畫面並排對比構圖方式可以回顧: 10-7 Human EPTZ Automatic Framing Sample Tutorial
最終驗證
請按下左下角的 「Build and RUN」執行專案:
1. 按下左下角的 「Build and RUN」 執行專案。
2. 建議您準備一段「有人在白板或黑板前寫字走動」的測試影片 ( 或請同事在鏡頭前假裝寫白板 )。
3. 先點擊 START RECEIVER ( 啟動接收 ):此時您會看到一個單純且完整的原始全螢幕畫面,講師正在畫面中走動。
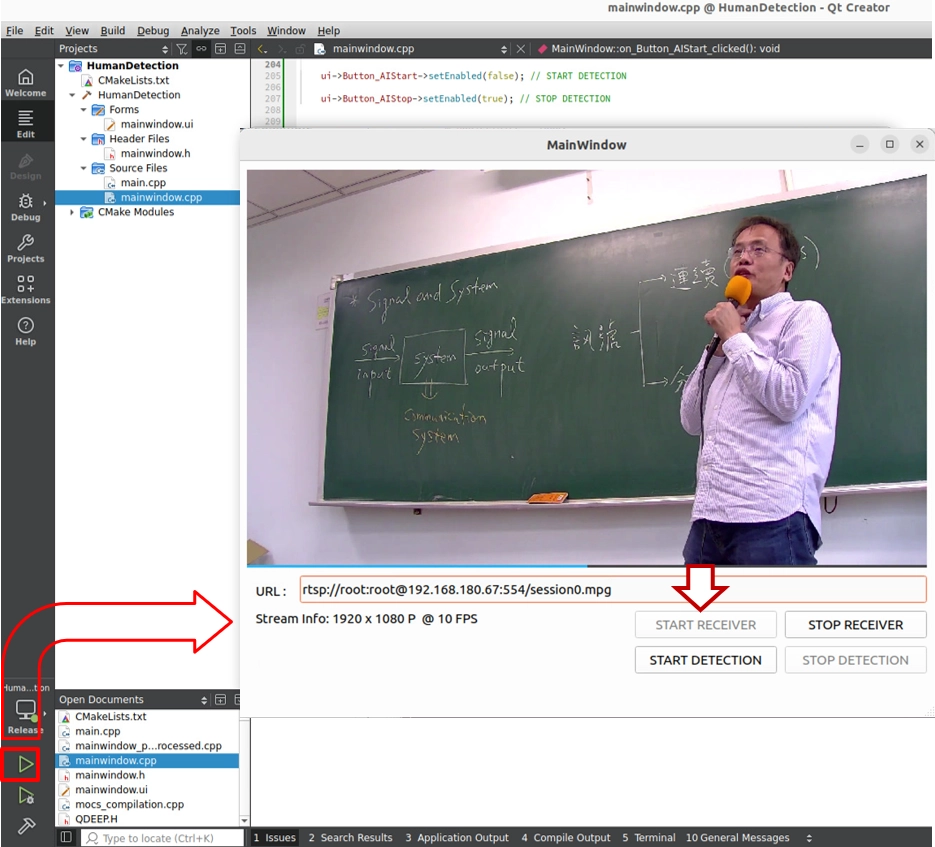
4. 接著,點擊 START DETECTION ( 啟動偵測 )!
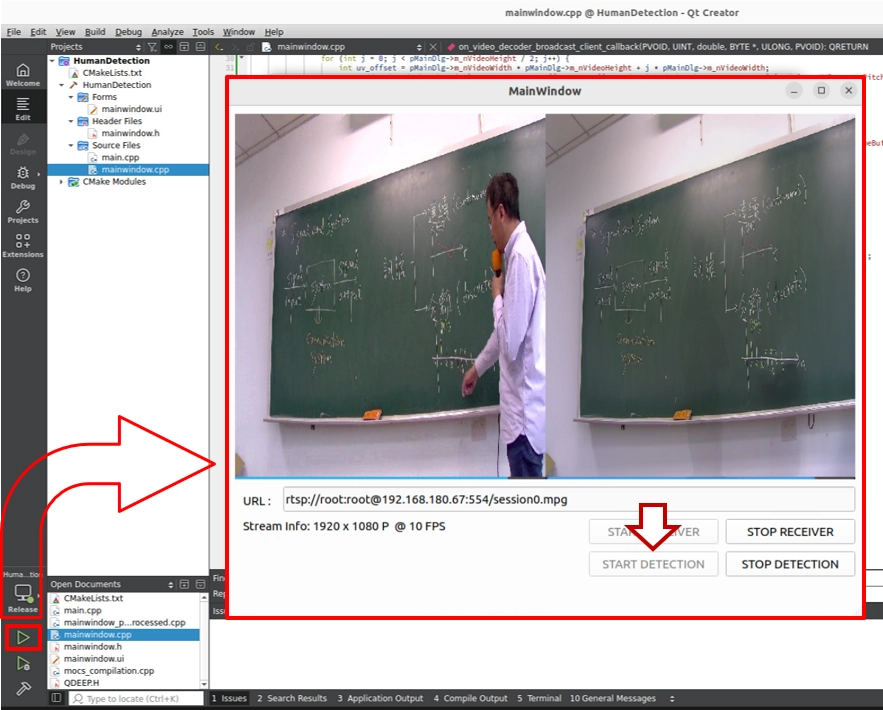
測試結果 : 畫面將會從中間一分為二:
• 左半邊視窗 ( 原圖 ) : 講師依然在黑板前走來走去,身體擋住了背後的字跡。
• 右半邊視窗 ( AI 處理 ) : 講師整個人完全消失在畫面中!AI 透過影像時間軸的背景建模技術,完美還原了講師背後那些被擋住的板書字跡。無論左邊的講師怎麼移動,右邊的黑板始終保持乾淨且清晰可見!