10-12 人物背景模糊功能範例教學
在前面的章節中,我們學會了各種「找東西」的技巧:找車子、找人臉、甚至精準抓出手指的 21 個關鍵點。我們處理 AI 結果的方式,不外乎就是拿到座標後,用 OpenCV 在畫面上「畫框、畫點、畫線」。
但如果今天客戶的需求是:「我要像 Google Meet 或 Teams 一樣,把視訊畫面裡的人保留,但把背後雜亂的房間背景給模糊掉」呢?
歡迎來到影像 AI 的另一個領域 —— 影像分割與處理!本章節我們將導入「人物背景模糊模型」。在這裡,您的開發思維將迎來一次巨大的翻轉:我們不再自己手動畫圖了,AI 引擎會直接在底層幫我們「算出一張」處理好的高畫質影像!
學習目標
透過本章節,您將學會:
1. 全新 Custom API : 透過屬性設定 API,動態調整背景模糊的強度 ( 高斯模糊大小 )。
2. 宣告 ImageBuffer : 學習如何手動配置一塊記憶體,讓 AI 引擎有空間將「處理完的整張圖片」倒出來給我們。
3. 畫圖方式的顛覆 : 不再使用 cv::rectangle 或 cv::line,而是直接將 AI 吐出的記憶體陣列,轉換為 OpenCV 的圖片並替換原圖。
4. 解構子與記憶體管理 : 確實釋放我們配置的 ImageBuffer 避免記憶體洩漏 。
準備工作
這次的模型包與以往稍微不同,請找到 Segmentation Person 模型壓縮檔(檔名可能標示為 SEGMENTATION.PERSON 相關字樣),將其解壓縮後,把裡面的 QDEEP.OD.SEGMENTATION.PERSON.LIGHT.CFG ( 設定檔 ) 以及所有對應的權重檔,一併複製到您 Qt 專案的建置輸出目錄下即可。
 核心 API 要怎麼改?
核心 API 要怎麼改?
請開啟您的專案,改變模型配置類型,在 QDEEP_CREATE_OBJECT_DETECT 中,請將 Enum 換成 QDEEP_OBJECT_DETECT_CONFIG_MODEL_HUMAN_BACKGROUND_BLURRING。
QDEEP_CREATE_OBJECT_DETECT
這是建立 AI 引擎並載入大腦(模型)的最關鍵 API。使用者必須透過此 API 初始化偵測器。

QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY
在載入背景模糊模型後,我們需要透過一支全新的 Custom API 來與 AI 引擎溝通,動態調整它的特效強度。這支 API 提供了極大的擴充彈性,讓您可以根據需求設定特定的屬性數值。

QDEEP_OBJECT_DETECT_BOUNDING_BOX 結構體
在我們過去的實作中,AI 回傳的 QDEEP_OBJECT_DETECT_BOUNDING_BOX 結構體通常只會填入 nX 、 nY (座標)或是 sKeypoints (骨架點)。但在「影像分割 ( Segmentation )」或「背景模糊」這類高階模型中,AI 要吐給我們的不再是幾個數字,而是一張完整的影像!
為此,在這個結構體中準備了一個專屬的指標參數: pImageResultBuffer ,在 AI 引擎啟動前,開發者必須手動配置一塊足夠大的記憶體空間並綁定給它。當 AI 處理完背景模糊後,就會將算好的高畫質影像像素(BGRA 格式)直接倒進這塊記憶體中供我們提取!

撰寫核心程式碼
請開啟您的專案,我們來進行最核心的程式碼修改:
模型載入與 Custom API 設定
在建構子 MainWindow::MainWindow(...) 中,換上背景模糊專屬的模型設定 QDEEP_OBJECT_DETECT_CONFIG_MODEL_HUMAN_BACKGROUND_BLURRING。在建立好偵測器後,我們要呼叫一支全新的 API: QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY 。它可以讓我們動態調整底層演算法的各項參數,這次我們要設定的是「背景模糊的範圍 ( 0~100 )」。
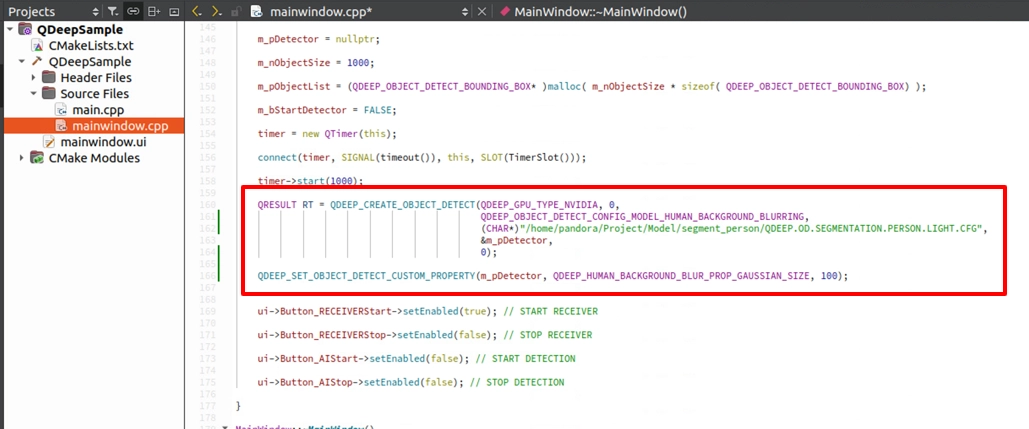
在連線成功時,宣告 ImageBuffer
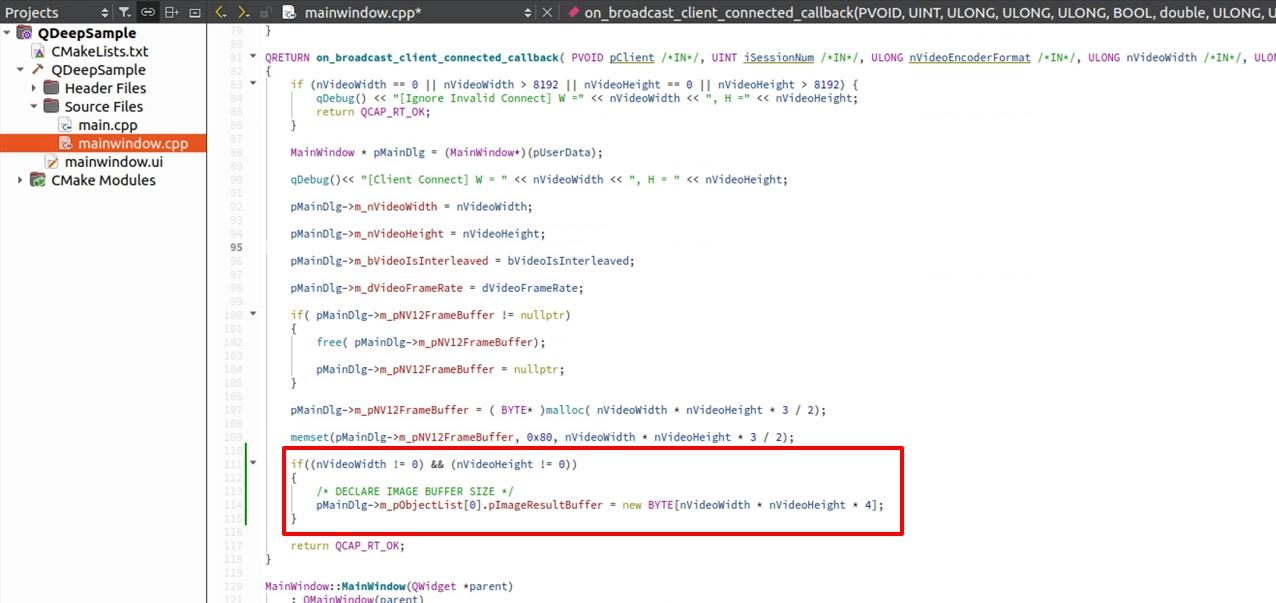
以往 AI 只是回傳「幾個座標數字」,記憶體佔用極小。但這次 AI 要回傳的是「整張背景模糊處理後的圖片」!因此,我們必須自己準備一個夠大的「容器 (Buffer)」,並將它綁定在 m_pObjectList 身上讓 AI 使用。
請前往 on_broadcast_client_connected_callback ( 當取得影像解析度時 ):
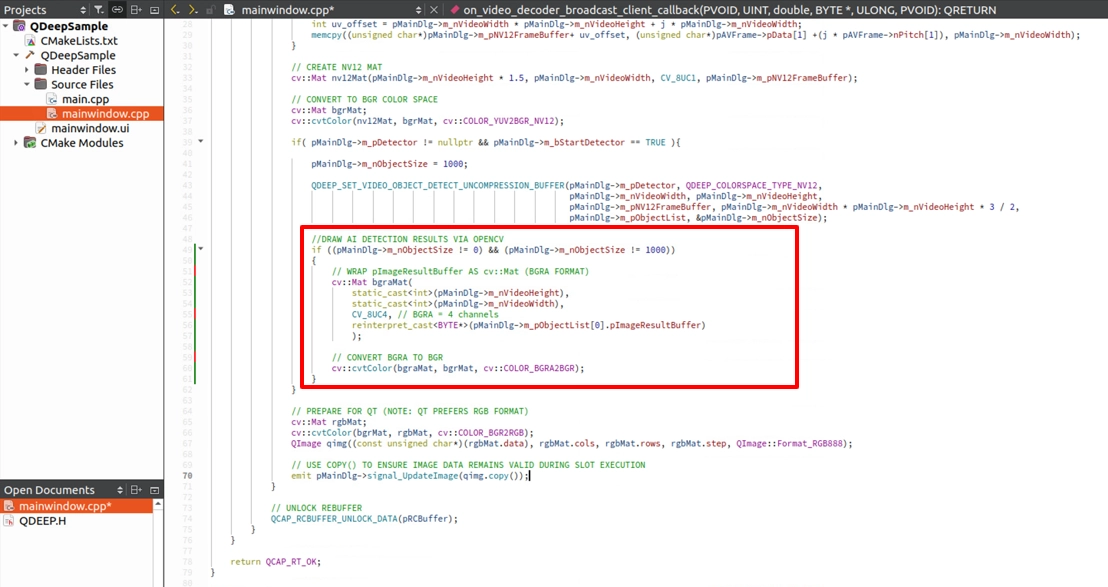
OpenCV 繪圖畫圖方式的修改
請前往 on_video_decoder_broadcast_client_callback 回呼函式。 這裡的畫圖邏輯將迎來大逆轉:我們不用畫框了!我們直接把那塊裝滿 AI 心血的 ImageBuffer 拿出來,蓋掉原本的畫面!
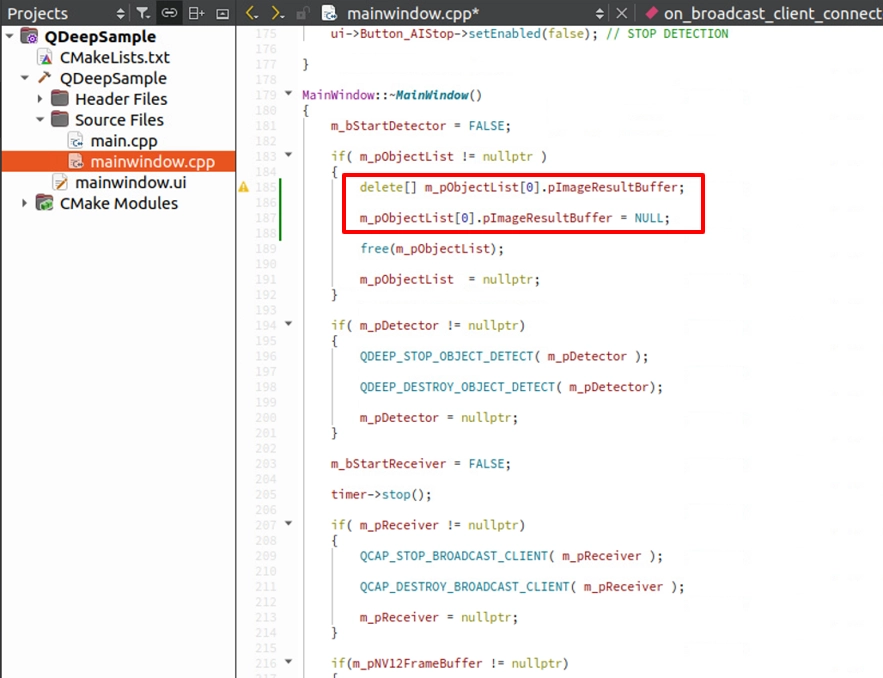
解構子與釋放資源
C++ 的鐵則:「有 new 就要有 delete」。 我們在上面步驟中手動 new 了一塊極大的 ImageBuffer 記憶體。如果我們在關閉程式(或是按下 Stop 按鈕)時沒有將其釋放,將會造成嚴重的記憶體洩漏!請在解構子 ~MainWindow() 中,確實補上釋放記憶體的動作:
最終驗證
請按下左下角的 「Build and RUN」 執行專案:
1. 啟動接收與偵測。
2. 請您走到鏡頭前,看看身後的畫面!
➤ 溫馨小叮嚀 ( 非常重要 ) : 在您第一次 開啟這支軟體 ( 執行程式 ) 的瞬間,介面可能會需要稍等一下才會顯示出來,請不要緊張!這是因為我們將「載入 AI 模型」的邏輯寫在了程式的建構子內。模型在首次執行時必須進行初始化配置,此時系統正努力將龐大的神經網路權重檔載入到 GPU 中。只要軟體成功開啟(首次載入完成),代表 AI 大腦已經在背景準備就緒!後續當您再次開啟軟體時,就不需要這個初始化的等待時間了!
您會發現,畫面中的您依然清晰銳利,但您背後的辦公室、凌亂的雜物,全部被套上了一層極度平滑的「高斯模糊」!如果您想挑戰進階玩法,可以嘗試在 UI 介面上加一個「拉桿 (QSlider)」,並將拉桿的數值綁定到 Custom API 參數中,您就能做出一套「可以即時微調背景模糊強度」的專業視訊特效軟體了!
透過這個章節,您不僅跨出了純粹「物件偵測」的領域,更掌握了高階的記憶體 Buffer 管理 與 影像通道轉換 (BGRA to BGR) 技術。這意味著未來無論遇到多複雜的 AI 影像處理模型,您都已經具備了強大的底層駕馭能力!