10-12 人物背景ぼかし機能サンプルチュートリアル
前の章では、さまざまな「ものを見つける」技術を学びました。車を見つける、人の顔を見つける、さらには指の21個のキーポイントを正確に取得する、といった内容です。AI の結果を処理する方法は、基本的には座標を取得した後、OpenCV を使って画面上に「枠を描く、点を描く、線を描く」というものでした。
しかし、今回の顧客要件が「Google Meet や Teams のように、ビデオ内の人物はそのまま残し、背後の散らかった部屋の背景だけをぼかしたい」だったらどうでしょうか。
画像 AI のもう一つの領域、画像セグメンテーションと画像処理へようこそ。本章では、「人物背景ぼかしモデル」を導入します。ここでは、開発の考え方が大きく変わります。私たちはもう手動で図形を描画しません。AI エンジンが低レベルで直接、処理済みの高画質画像を計算して出力してくれます。
学習目標
本章を通して、以下を学びます。
1. 新しい Custom API : 属性設定 API を通して、背景ぼかしの強度、つまりガウシアンぼかしサイズを動的に調整します。
2. ImageBuffer の宣言 : AI エンジンが「処理後の画像全体」を出力できるように、手動でメモリ領域を確保する方法を学びます。
3. 描画方法の転換 : cv::rectangle や cv::line は使用せず、AI が出力したメモリ配列を直接 OpenCV の画像へ変換し、元画像を置き換えます。
4. デストラクタとメモリ管理 : 確保した ImageBuffer を確実に解放し、メモリリークを防ぎます。
準備作業
今回のモデルパッケージは、これまでのものと少し異なります。Segmentation Person モデルの圧縮ファイルを見つけてください。ファイル名には SEGMENTATION.PERSON に関連する文字列が含まれている場合があります。解凍後、内部の QDEEP.OD.SEGMENTATION.PERSON.LIGHT.CFG (設定ファイル)と、対応するすべての重みファイルを、Qt プロジェクトのビルド出力ディレクトリへまとめてコピーしてください。

コア API はどのように変更するのか
プロジェクトを開き、モデル設定タイプを変更してください。 QDEEP_CREATE_OBJECT_DETECT で、Enum を QDEEP_OBJECT_DETECT_CONFIG_MODEL_HUMAN_BACKGROUND_BLURRING に変更します。
QDEEP_CREATE_OBJECT_DETECT
これは AI エンジンを作成し、「頭脳」(モデル)を読み込むための最も重要な API です。ユーザーはこの API を通して検出器を初期化する必要があります。
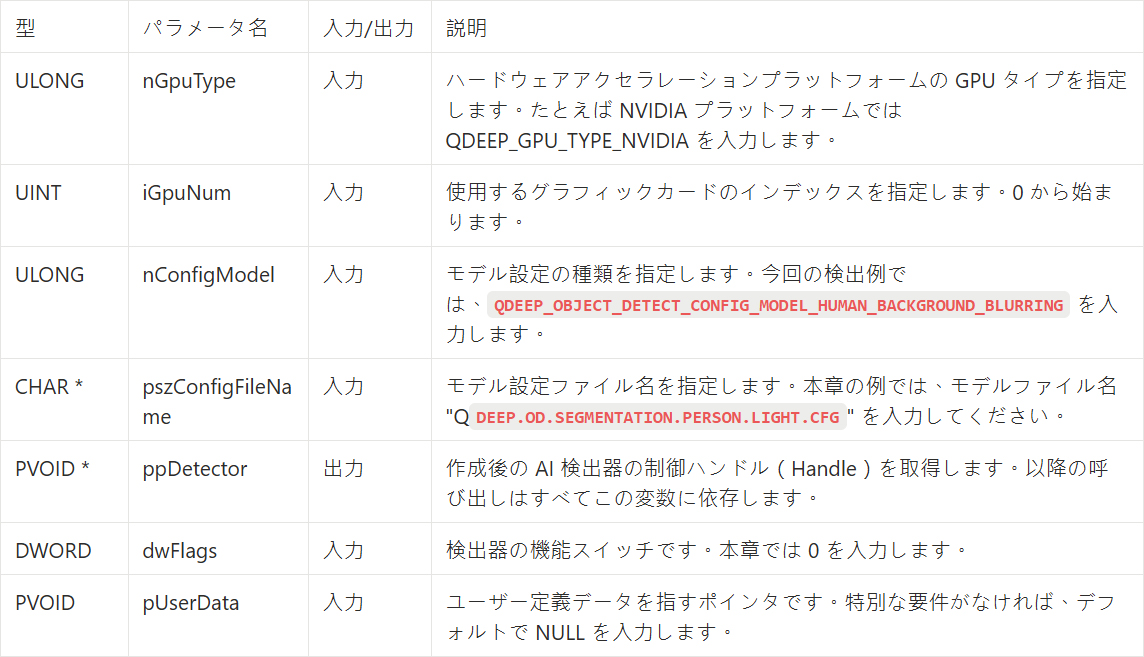
QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY
背景ぼかしモデルを読み込んだ後、AI エンジンと通信し、特殊効果の強度を動的に調整するために、新しい Custom API を使用する必要があります。この API は非常に高い拡張性を提供し、必要に応じて特定の属性値を設定できます。
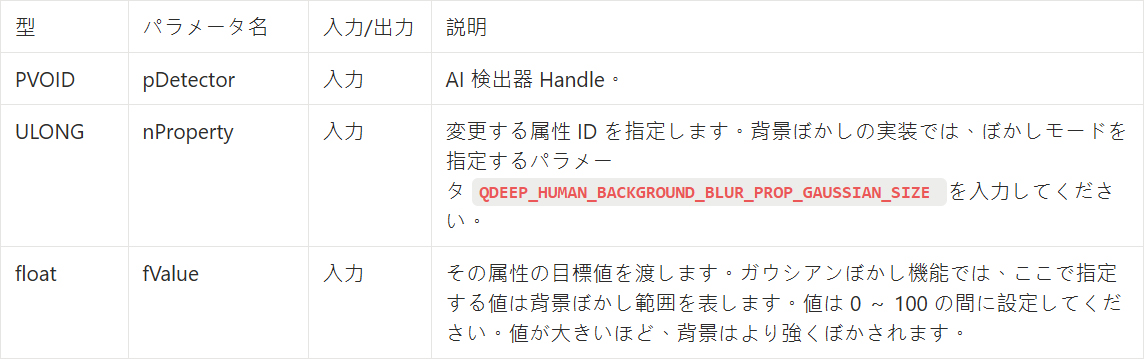
QDEEP_OBJECT_DETECT_BOUNDING_BOX 構造体
これまでの実装では、AI が返す QDEEP_OBJECT_DETECT_BOUNDING_BOX 構造体には、通常 nX、 nY (座標)、または sKeypoints (骨格点)が入るだけでした。しかし、「画像セグメンテーション(Segmentation)」や「背景ぼかし」のような高度なモデルでは、AI が返すものは数値だけではなく、 完全な画像になります。
そのため、この構造体には専用のポインタパラメータ pImageResultBuffer が用意されています。AI エンジンを起動する前に、開発者は十分な大きさのメモリ領域を手動で確保し、このポインタにバインドする必要があります。背景ぼかし処理が完了すると、AI は計算済みの高画質画像ピクセル(BGRA 形式)を、このメモリ領域へ直接書き込みます。私たちはそこから結果を取得できます。

コアコードの作成
プロジェクトを開き、最も重要なコード変更を行いましょう。
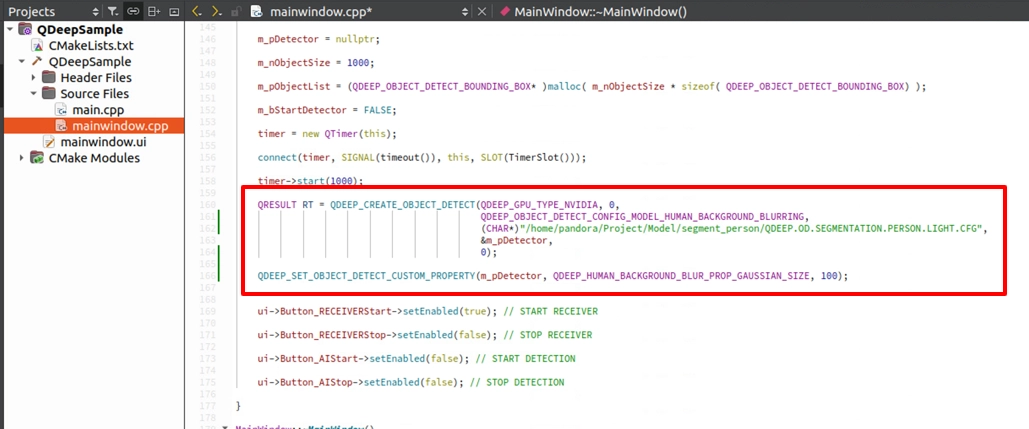
モデル読み込みと Custom API 設定
コンストラクタ MainWindow::MainWindow(...) の中で、背景ぼかし専用のモデル設定 QDEEP_OBJECT_DETECT_CONFIG_MODEL_HUMAN_BACKGROUND_BLURRING に切り替えます。検出器を作成した後、新しい API QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY を呼び出します。この API により、基盤アルゴリズムの各種パラメータを動的に調整できます。今回は「背景ぼかしの範囲(0~100)」を設定します。
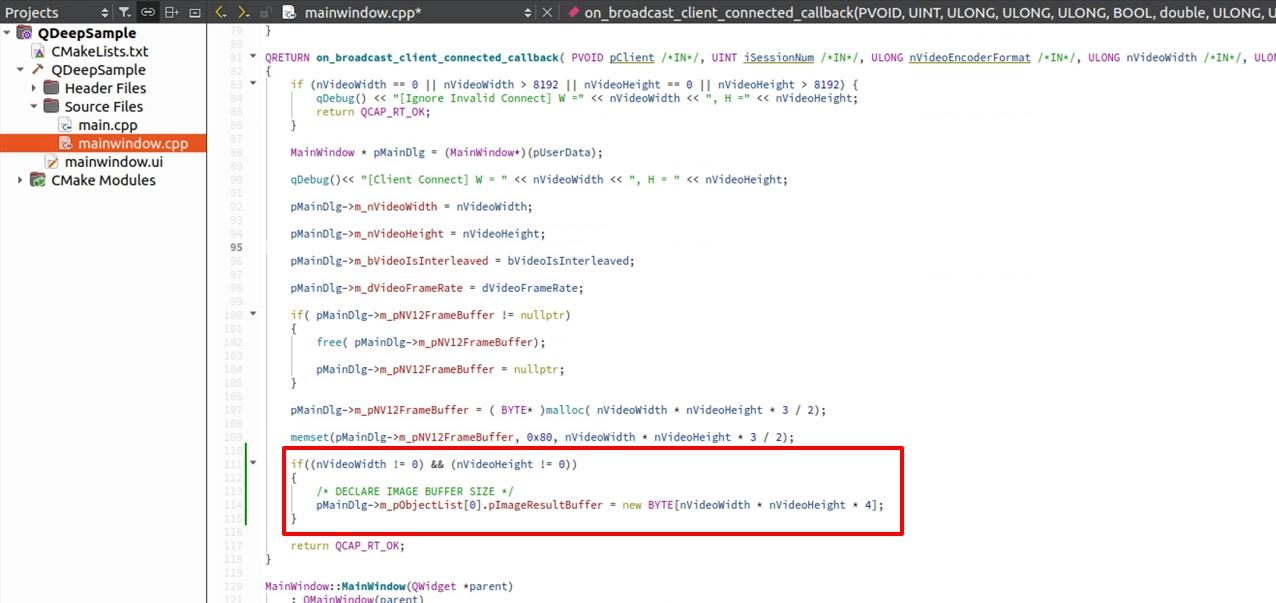
接続成功時に ImageBuffer を宣言する
これまで AI は「いくつかの座標値」を返すだけだったため、メモリ使用量は非常に小さいものでした。しかし今回は、AI が「背景ぼかし処理後の画像全体」を返します。そのため、十分な大きさの「コンテナ(Buffer)」を自分で用意し、それを m_pObjectList にバインドして AI に使用させる必要があります。
画像解像度を取得するタイミングで、 on_broadcast_client_connected_callback へ移動してください。
OpenCV の描画方法を変更する
on_video_decoder_broadcast_client_callback コールバック関数へ移動してください。ここでの描画ロジックは大きく変わります。もう枠を描く必要はありません。AI の処理結果が詰まった ImageBuffer を直接取り出し、元の画面を置き換えます。
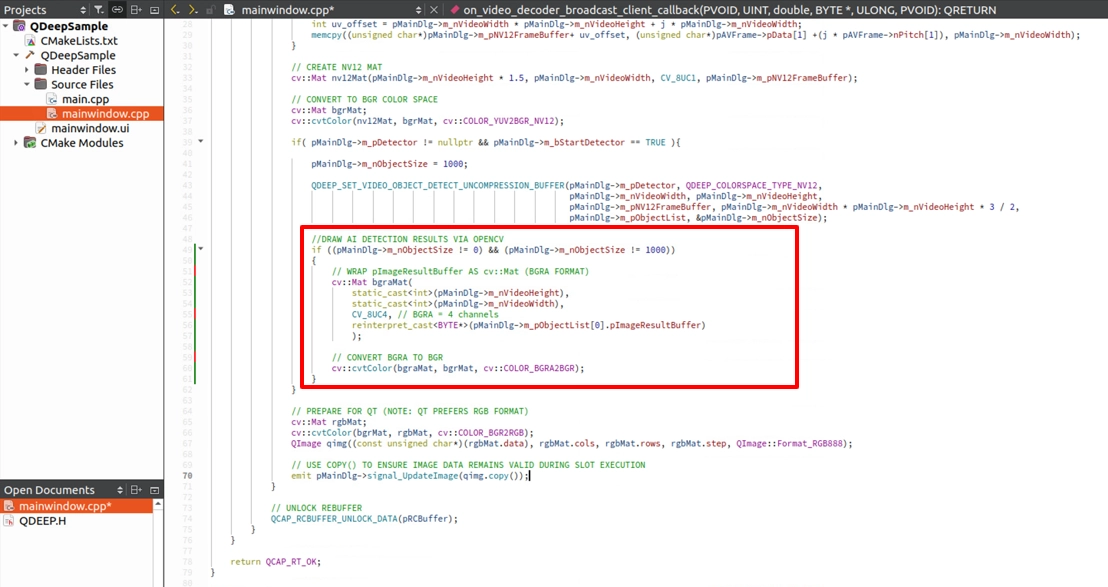
デストラクタとリソース解放
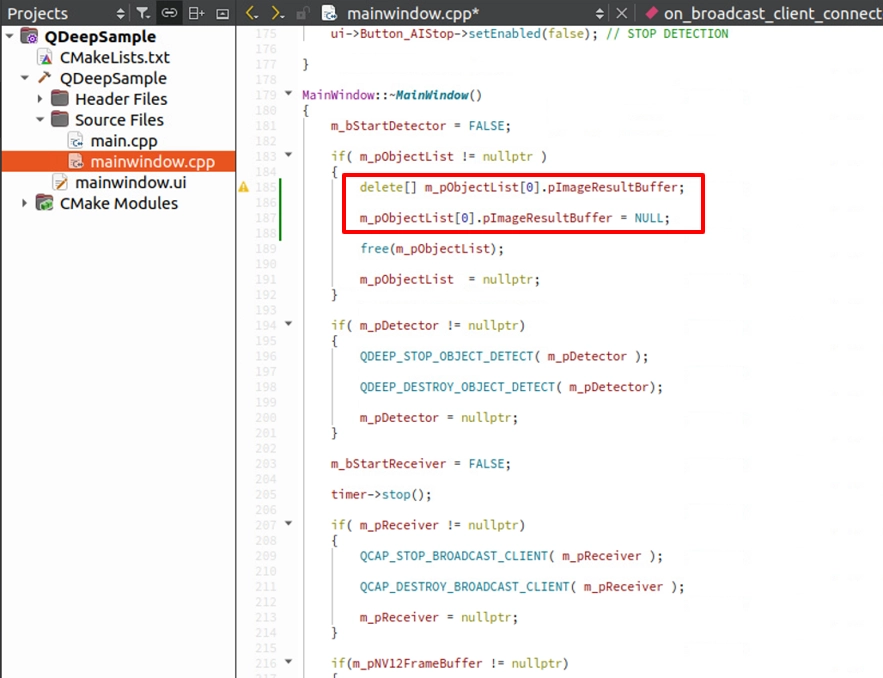
C++ の鉄則は、「 new があるなら delete も必要」です。上記の手順で、非常に大きな ImageBuffer メモリを手動で new しました。プログラムを終了するとき、または Stop ボタンを押したときにこれを解放しないと、深刻なメモリリークが発生します。デストラクタ ~MainWindow() の中で、必ずメモリ解放処理を追加してください。
最終確認
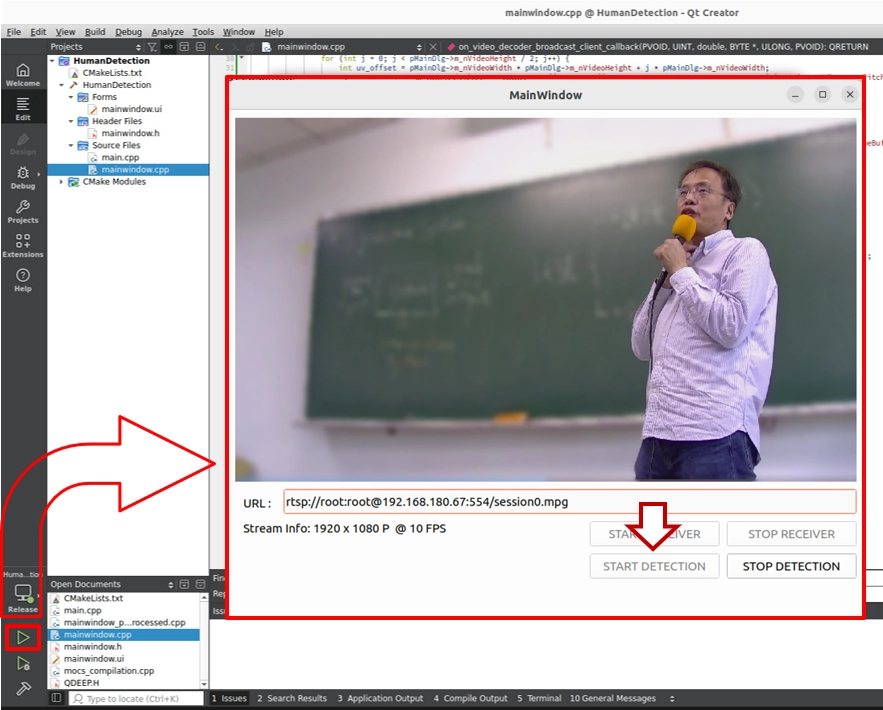
左下の 「Build and RUN」クリックしてプロジェクトを実行してください。
1. 受信と検出を開始します。
2. カメラの前に立ち、自分の後ろの映像を確認してください。
➤ 補足リマインダー(非常に重要): 初めてこの ソフトウェアを起動する(プログラムを実行する)瞬間、インターフェースが表示されるまで少し時間がかかる場合があります。心配しないでください。これは「AI モデルを読み込む」ロジックをプログラムのコンストラクタ内に書いているためです。初回実行時にはモデルの初期化設定が必要であり、システムは巨大なニューラルネットワークの重みファイルを GPU に読み込んでいます。ソフトウェアが正常に起動した時点で、AI の頭脳はバックグラウンドで準備完了です。次回以降にソフトウェアを起動するときは、この初期化待ち時間は不要になります。
画面内のあなたはそのまま鮮明に表示されますが、背後のオフィスや散らかった物は、非常に滑らかな「ガウシアンぼかし」で覆われていることがわかるでしょう。さらに高度な応用に挑戦したい場合は、UI に「スライダー(QSlider)」を追加し、そのスライダーの値を
Custom API のパラメータへバインドしてみてください。これにより、「背景ぼかしの強度をリアルタイムに微調整できる」プロフェッショナルなビデオエフェクトソフトウェアを作成できます。
この章を通して、単なる「物体検出」の領域を越えるだけでなく、高度なメモリ Buffer 管理と画像チャンネル変換(BGRA to BGR)の技術も習得しました。これは、今後どれほど複雑な AI 画像処理モデルに出会っても、それを低レベルから制御できる強力な基礎力をすでに身につけたことを意味します。