10-2 建立 AI 基礎樣板專案:QDeepSample
歡迎回到第 10 章的實戰環節!在上一節中,我們已經為大家揭開了 QDEEP 引擎的神秘面紗,並了解了 AI 影像分析的標準 S.O.P(接收串流 ➔ 解碼 ➔ AI 引擎推論 ➔ OpenCV 繪圖)。
為了避免未來每次實作新的 AI 功能時,都要陷入重複撰寫「拉 UI、接串流、設定環境」的繁瑣輪迴,今天這堂課,我們只有一個核心任務:動手打造一個萬用的「AI 視覺分析基礎樣板 ( QDeepSample )」!
在這個樣板中,我們會將前面章節學過的「RTSP 接收端技術」與「OpenCV 影像處理庫」完美結合。我們今天的最終目標,是「順利看見接收到的串流畫面」,並為下一章即將加入的 AI 辨識模型準備好最乾淨的運作框架。一旦建立好這個基底,未來無論是實作人形偵測、人臉辨識還是車牌分析,您都只需要「複製這個樣板 ➔ 替換模型 ➔ 加上幾行核心 API 以及修改繪圖方式」,就能瞬間完成開發!
➤ RTSP 接收端概念可以回顧: 9-9 RTSP 串流接收端功能範例教學
現在,請開啟您的 Qt Creator,跟著我們一步步打好這座堅不可摧的 AI 開發地基吧!
建立專案與準備核心依賴檔案
首先,請參考我們在第 9 章學過的步驟,在 Qt Creator 中建立一個全新的 Qt Widgets Application,並將專案命名為 QDeepSample。
➤ 建立基礎樣板可以回顧: 9-3 建立基礎樣板專案:Hello NexVDO SDK!
為了讓這個專案同時具備「接收網路串流」與「AI 分析」的能力,我們必須將 SDK 的核心檔案放入專案目錄中
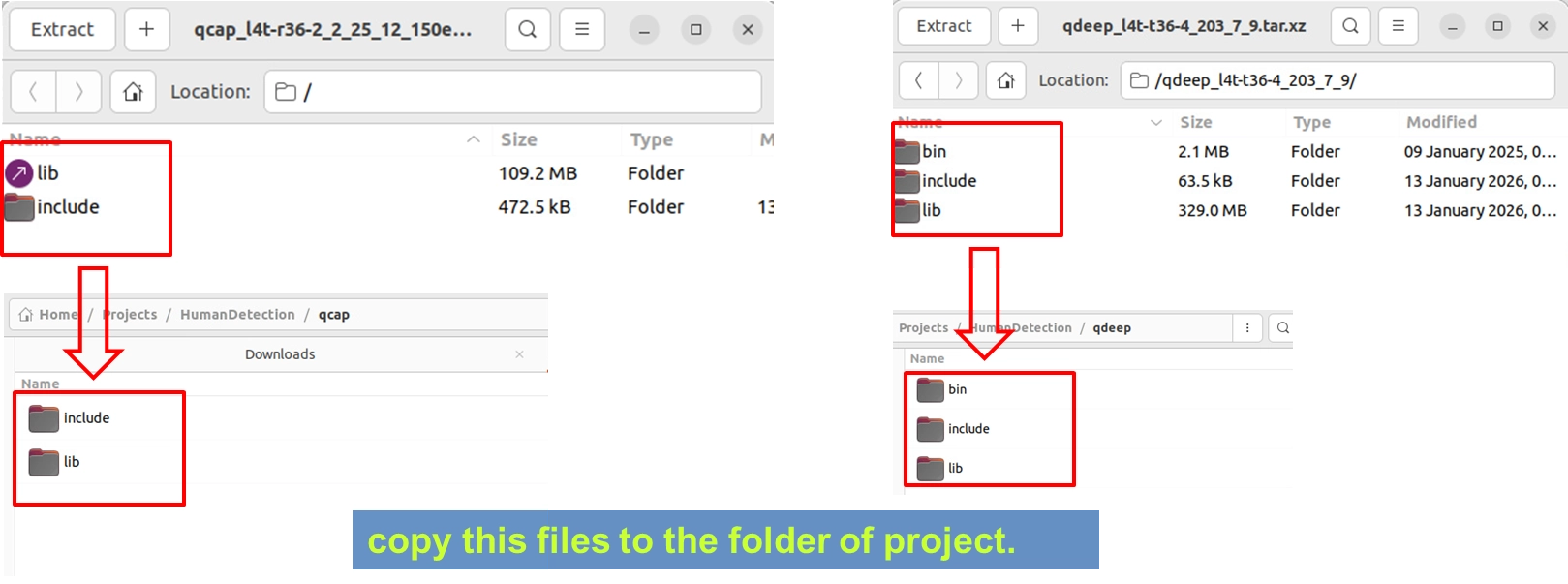
1. 匯入 SDK 函式庫: 請將您解壓縮後的 NexVDO SDK 資料夾打開,分別找到 qcap 與 qdeep 兩個資料夾,將裡面的 include 與 lib 資料夾完整複製到您的 QDeepSample 專案目錄下。
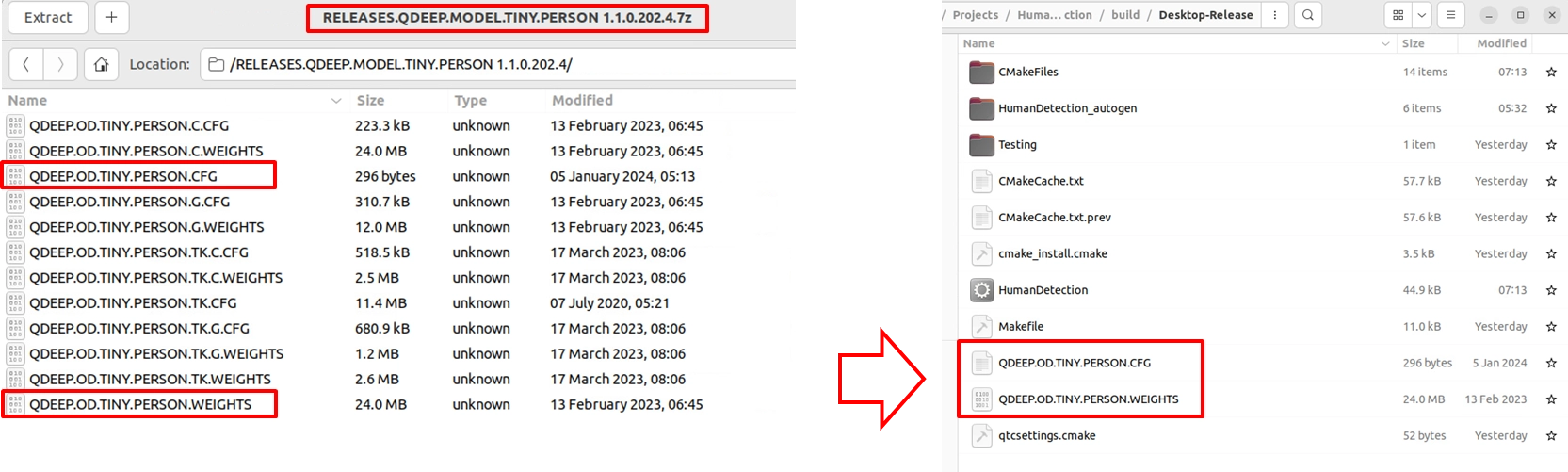
2. 匯入 AI 模型檔案 (Models): 在正式呼叫 QDEEP 引擎前,我們需要把預先訓練好的模型檔案準備好。請將聰泰提供的模型壓縮檔解壓縮(例如 Tiny Person 模型),並將結尾為 .CFG (設定檔)與 .WEIGHTS (權重檔)的檔案,複製到您專案的建置輸出目錄下(通常是 build-Release... 資料夾內)。
設定 CMakeLists.txt ( 串聯 OpenCV 與 SDK )
當牽涉到 AI 辨識,畫面的渲染邏輯將會與單純的播放器不同。為了把 AI 引擎回傳的「座標數據」畫成我們常見的綠色、紅色「辨識追蹤框」,我們必須借用強大的開源影像處理庫:OpenCV。
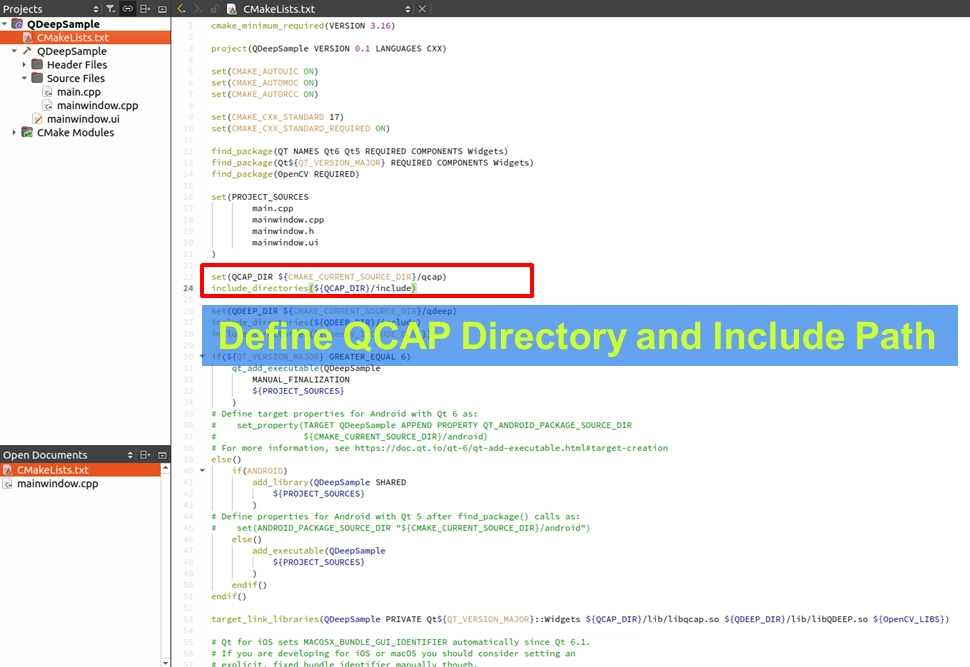
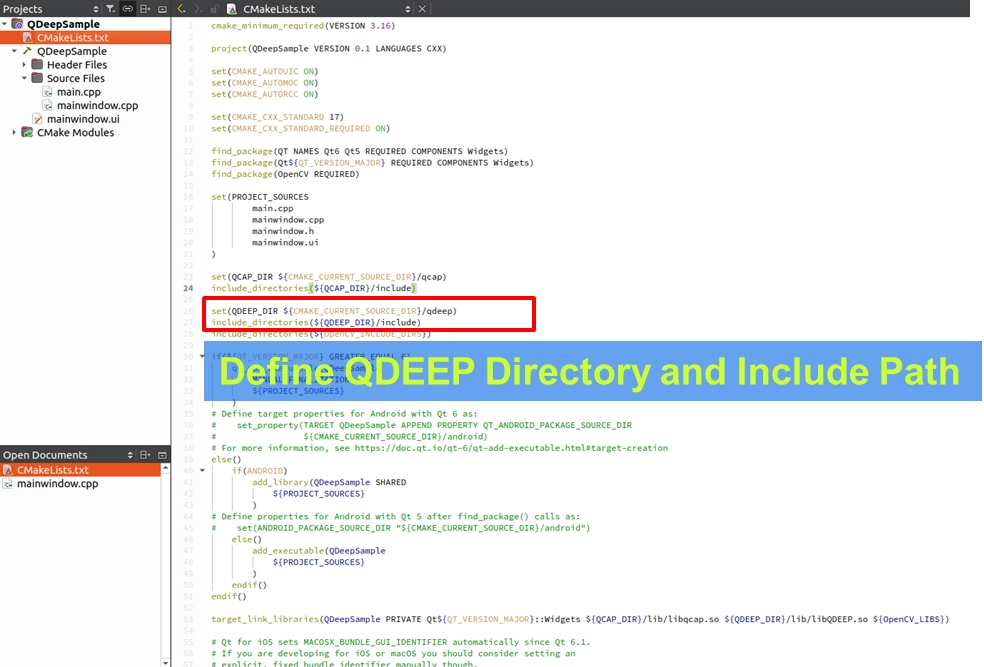
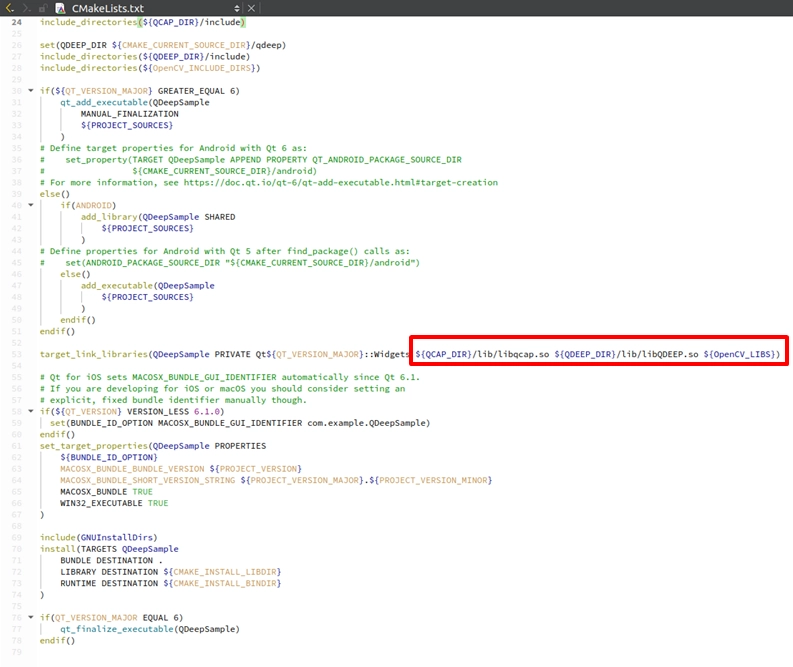
請開啟專案中的 CMakeLists.txt,我們要把 QCAP、QDEEP 以及 OpenCV 一次綁定到位:
1. 設定 SDK 路徑: 加入 QCAP_DIR 與 QDEEP_DIR的路徑定義,並使用 include_directories 包含它們的標頭檔。
2. 尋找並引入 OpenCV : 在 find_package(Qt6...)的下方,加入 find_package(OpenCV REQUIRED).

3. 連結所有 Library : 在最下方的 target_link_libraries 中,把 libqcap.so、 libQDEEP.SO以及 ${OpenCV_LIBS} 通通加進去!
打造標準 AI 測試 UI 介面
我們需要一個清晰、直覺的控制面板,來獨立控制「影像接收」與「AI 分析」的開關。請點開 mainwindow.ui ,佈置以下元件:
1. 網址輸入框 (QLineEdit) : 命名為 StrURL,用來輸入 RTSP 串流網址。
➤ 網址輸入框可以回顧: 9-9 RTSP 串流接收端功能範例教學
2. 串流控制按鈕 ( QPushButton ) : 拉兩個按鈕,分別命名為「START RECEIVER」與「STOP RECEIVER」,用來控制畫面拉取。
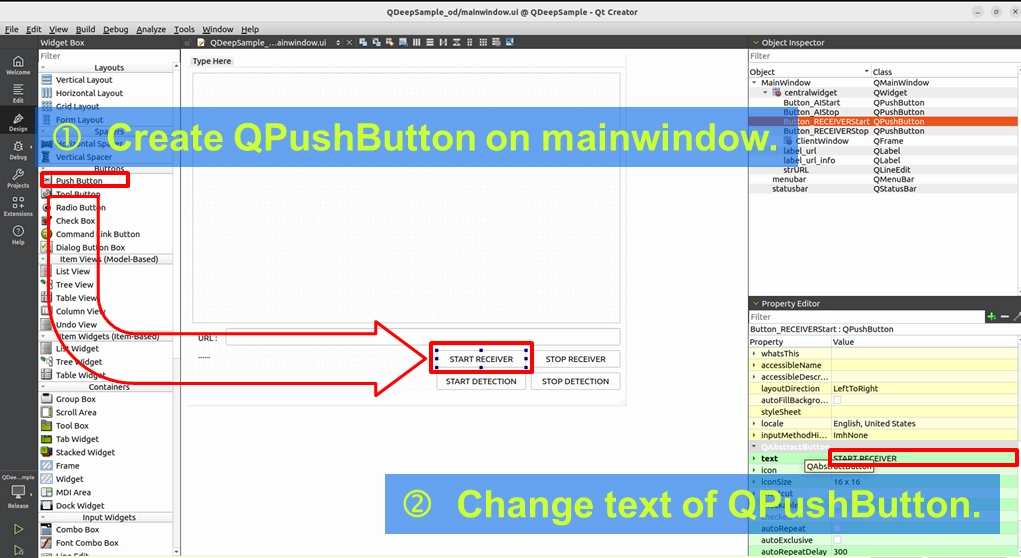
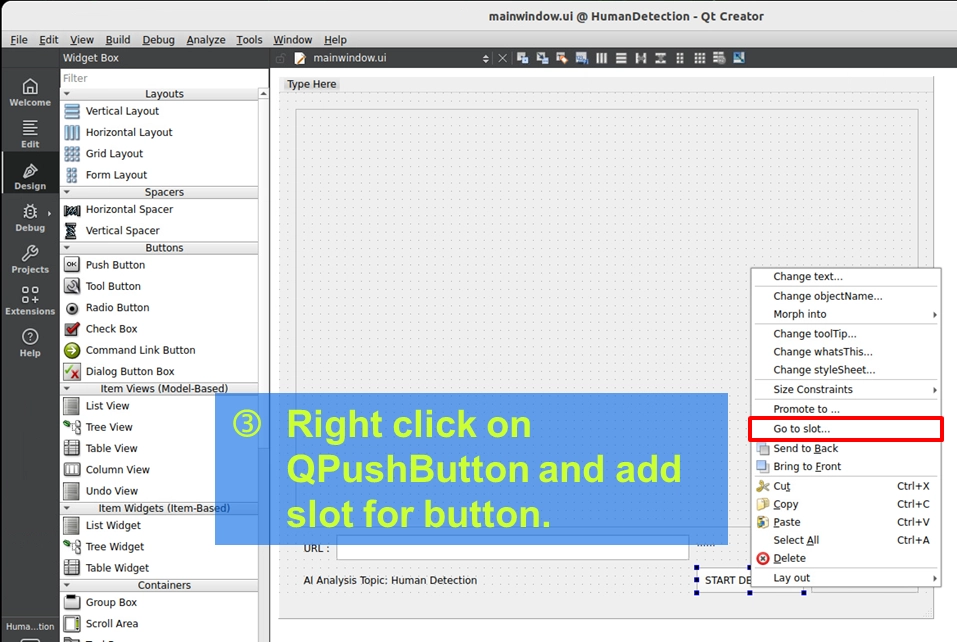
3. AI 控制按鈕 ( QPushButton ) : 再拉兩個按鈕,分別命名為「START DETECTION」與「STOP DETECTION」,這將是未來啟動 AI 模型的開關!
4. 顯示畫布 ( QFrame ) : 拉一個 QFrame 命名為 ClientWindow (或 PreviewWindow),這塊畫布稍後會交由 OpenCV 來負責繪製影像與辨識框。
➤ 拉取 QFrame 方式可以回顧: 9-3 建立基礎樣板專案:Hello NexVDO SDK!
標頭檔與核心變數宣告
為了讓專案能夠認得 NexVDO SDK 的強大功能,並為接下來的自訂繪圖預作準備,我們必須在 mainwindow.h中進行一系列的宣告。
引入 QCAP、QDEEP 與 Qt 繪圖標頭檔
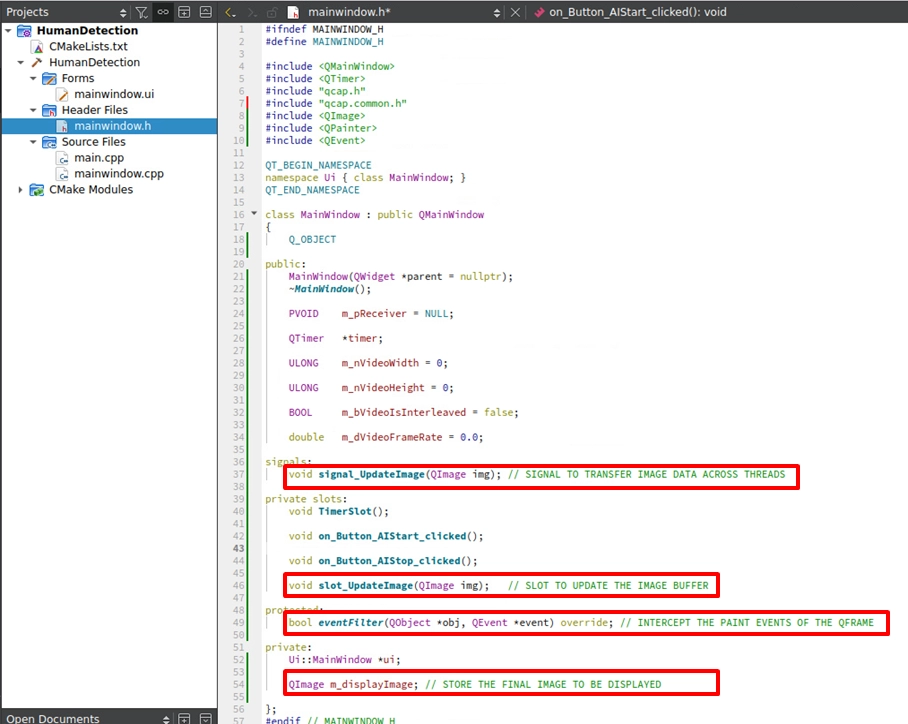
如圖所示,請打開 mainwindow.h ,在頂端引入以下三類不可或缺的標頭檔:
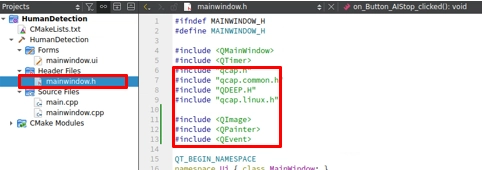
• QCAP 系列 ( qcap.h, qcap.common.h, qcap.linux.h ) : 這是我們喚醒 NexVDO SDK 擷取與接收底層能力的鑰匙。
• QDEEP 系列 ( QDEEP.H ) :雖然我們這章還沒正式啟動 AI 分析,但我們先把 AI 引擎的定義檔準備好,這是為了下一章能「無縫接軌」埋下的重要伏筆!
• Qt 繪圖系列 (
宣告核心變數與跨執行緒機制
宣告我們的主角:m_pReceiver ( 負責接收 RTSP )、m_pDetector ( 負責 AI 分析的 Handle ),以及相關參數:
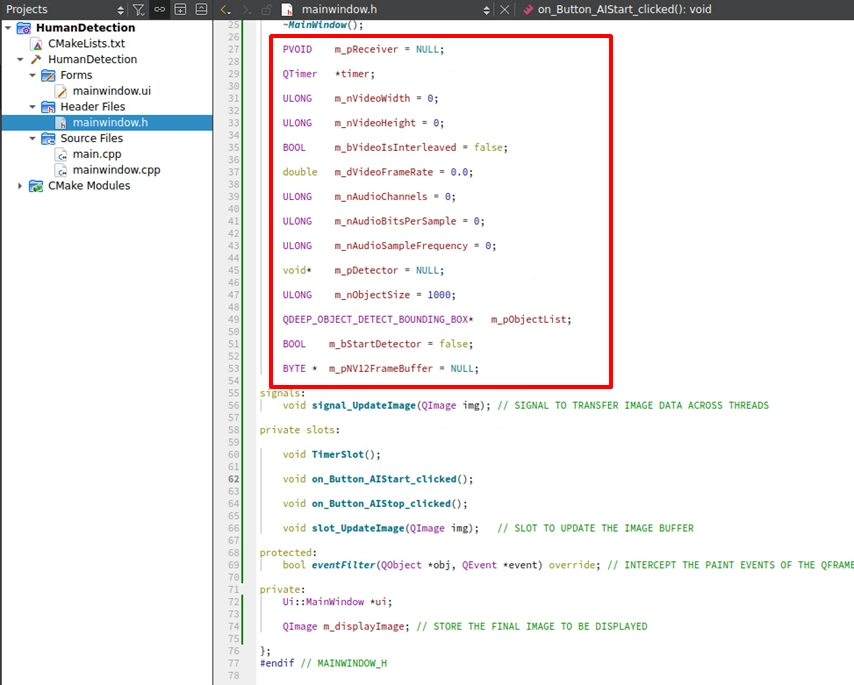
接著,在 MainWindow 類別中,宣告負責接收串流的 Handle: PVOID m_pReceiver = NULL;,以及用來儲存解碼後純淨影像的緩衝區指標:BYTE *m_pNV12FrameBuffer = NULL;。
此外,由於底層的擷取回呼函式 ( Callback ) 與 UI 介面屬於不同的執行緒,請務必宣告 signal_UpdateImage 與 slot_UpdateImage 來進行跨執行緒的畫面傳遞,並加入 eventFilter 和 m_displayImage 來攔截與重繪 UI 畫面。
變數初始化、UI防呆安全機制
在 C++ 的世界裡,「在使用變數前,請務必先將其初始化」是一個極為重要的安全守則!同時,我們也要在這個階段建立好 UI 按鈕的防呆骨架,以及視窗關閉時的資源釋放機制。
核心變數初始化
請開啟 mainwindow.cpp 的建構子 MainWindow::MainWindow(...) ,在 ui->setupUi(this);的下方,將我們剛剛在標頭檔宣告的所有變數,給予乾淨的初始值(如 : 0 或 NULL )。這樣能確保程式在後續判斷指標狀態時不會發生崩潰:
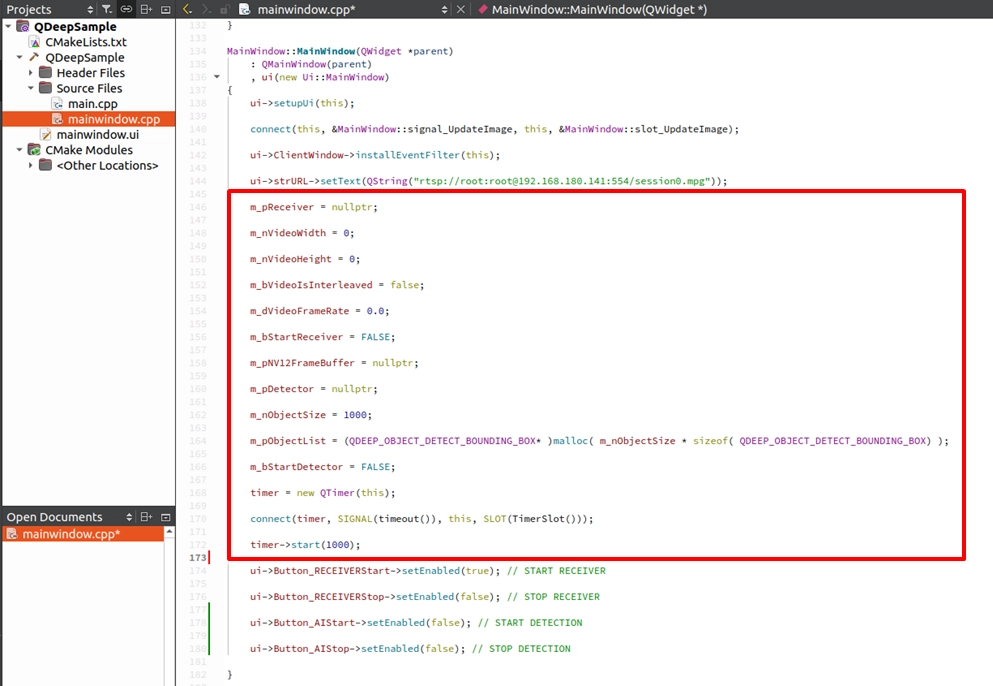
在程式剛啟動時,我們尚未開始接收串流,當然也不能啟動 AI 分析。同時,我們也要預防使用者在沒有按「STOP」的情況下,直接點擊視窗的「X」關閉軟體,導致網路連線卡死或記憶體洩漏。因此我們需要做好完善的保護機制。
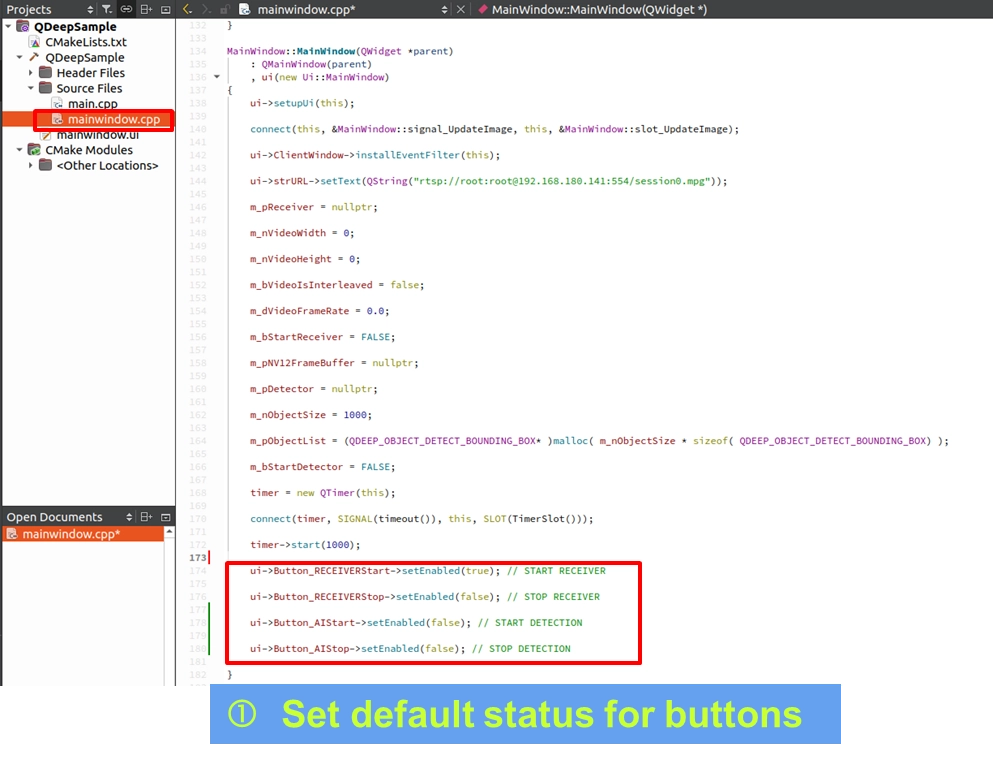
設定建構子中的按鈕預設狀態
打開 mainwindow.cpp,在程式一啟動時(也就是 MainWindow::MainWindow 建構子中),緊接著在變數初始化的下方,設定程式剛開啟時的按鈕防呆狀態(還沒連線不能按停止,還沒畫面不能啟動 AI):
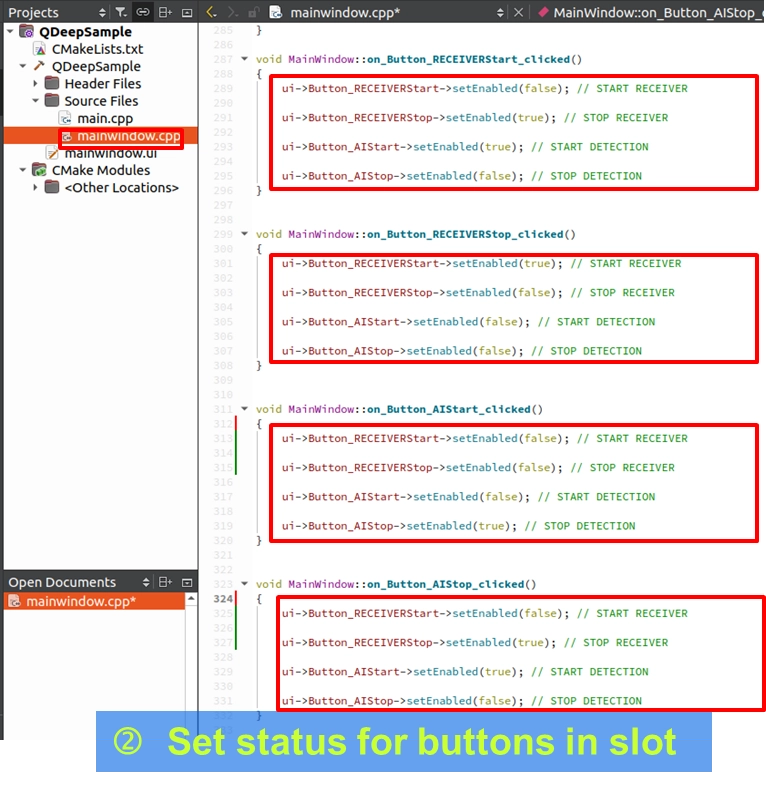
四個按鈕的狀態切換邏輯
在四個按鈕的槽函式中,我們先純粹把按鈕點擊後的「狀態連動 ( setEnabled )」寫好,打造出一個安全的控制流程。
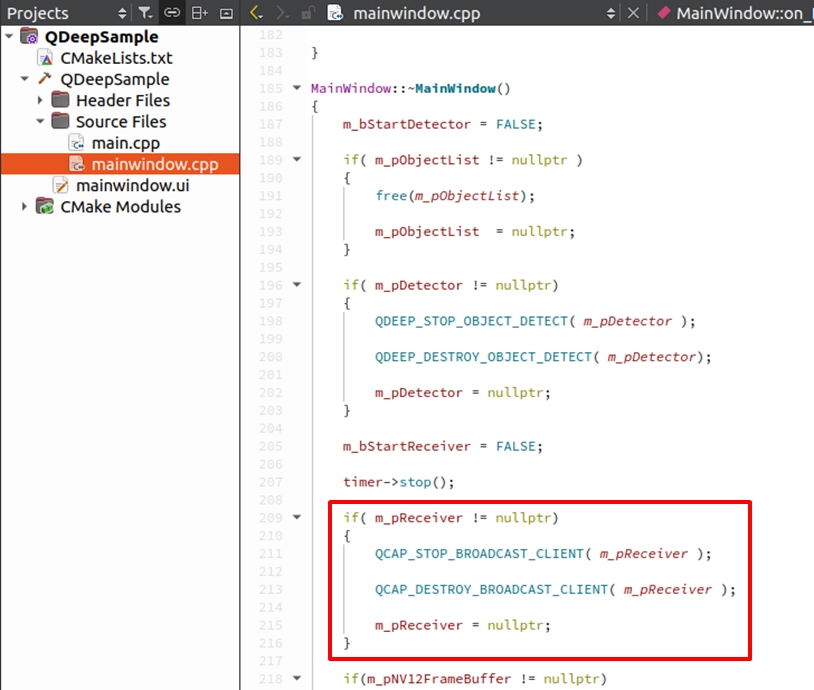
在解構子中釋放資源
確保這塊手動配置的記憶體在視窗關閉時被安全釋放,避免記憶體洩漏 ( Memory Leak ):
填入 RTSP 接收與連線邏輯
有了穩固的防呆機制後,我們終於可以把 RTSP 網路收流的核心 API 填補進去了!這個步驟完全還原了我們在先前的章節中學過的「接收端接收技巧」。
➤ RTSP 串流接收端可以回顧: 9-9 RTSP 串流接收端功能範例教學
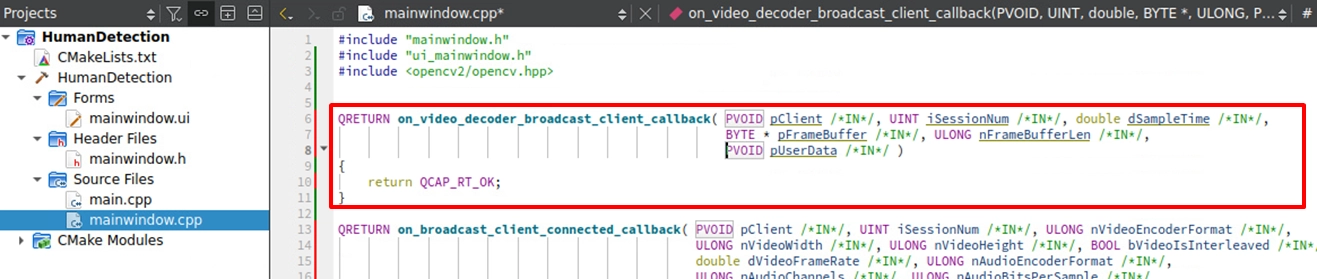
建立空的回呼函式 ( Callback )
在綁定 API 發起連線之前,我們必須先在 mainwindow.cpp 的上半部,建立兩個用來接收底層資訊的 Callback 總機。一個負責接收連線狀態 ( on_broadcast_client_connected_callback ),另一個負責攔截解碼後的純淨影像 ( on_video_decoder_broadcast_client_callback ) :

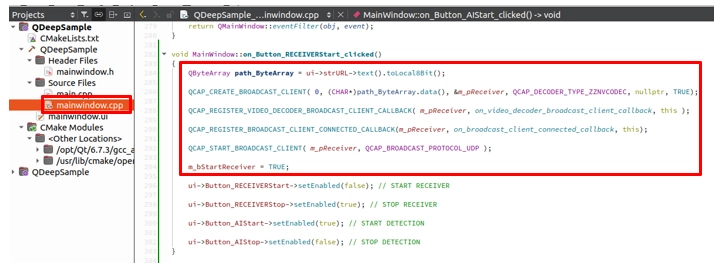
實作 START RECEIVER ( 啟動接收 )
回到 on_Button_RECEIVERStart_clicked() 槽函式中,在我們原本寫好的按鈕狀態切換 ( setEnabled ) 程式碼上方,正式加入發起連線的 API:
1. 讀取 StrURL 輸入框的網址。
2. 呼叫 QCAP_CREATE_BROADCAST_CLIENT 建立接收端。
3. 將兩隻 QCAP_REGISTER_VIDEO_DECODER_BROADCAST_CLIENT_CALLBACK 和 QCAP_REGISTER_BROADCAST_CLIENT_CONNECTED_CALLBACK註冊進去。
4. 呼叫 QCAP_START_BROADCAST_CLIENT 正式開始收流!
別忘了加上 m_bStartReceiver = TRUE; 來標記接收端已正式啟動。
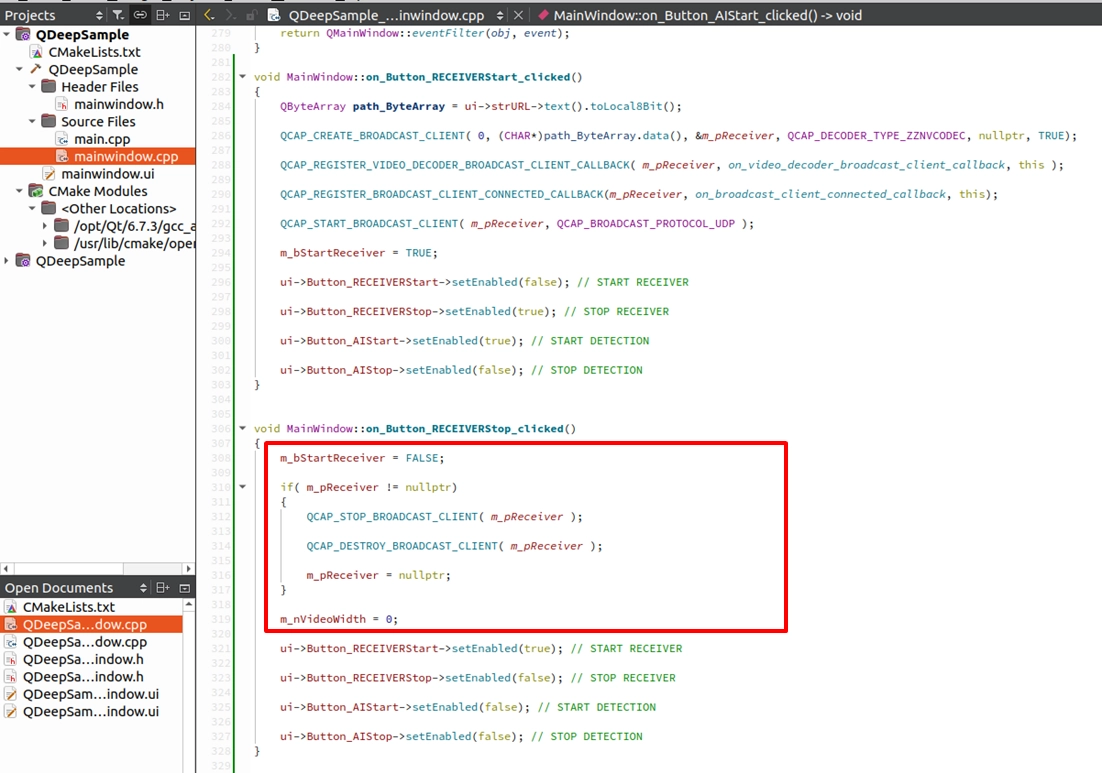
實作 STOP RECEIVER ( 停止接收 )
同樣地,在 on_Button_RECEIVERStop_clicked() 槽函式中,我們要加入安全下車的資源釋放 API,並重置相關的狀態變數:
動態配置 NV12 緩衝區
既然我們準備要把底層的影像複製出來,就必須為它準備一塊足夠大的記憶體空間(Buffer)。由於攝影機解析度是動態的,我們必須在「連線成功並取得長寬」的瞬間進行動態配置,並在專案關閉時確實釋放它。
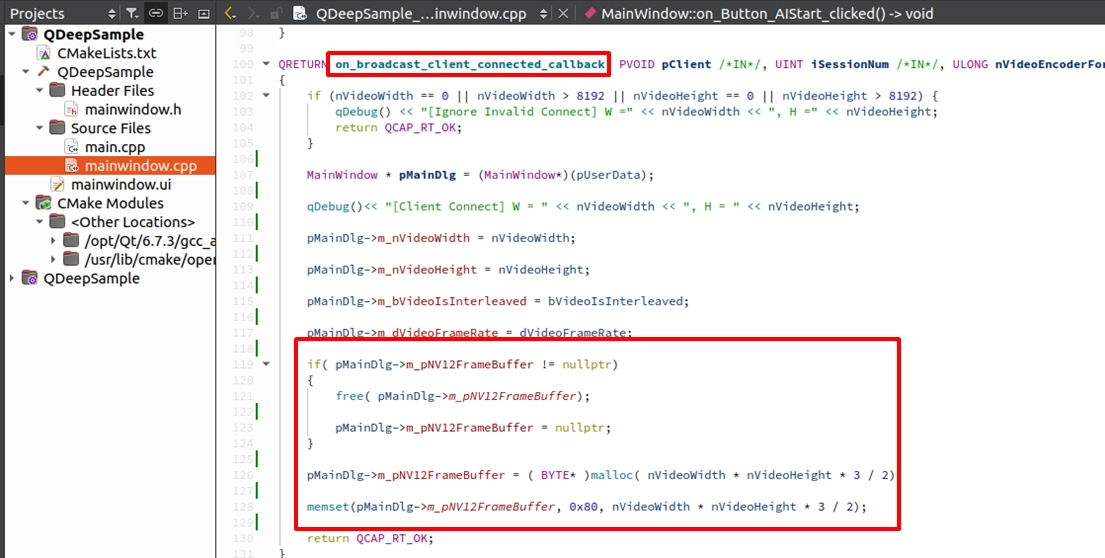
在連線回呼中配置記憶體
回到 on_broadcast_client_connected_callback 這個總機函式中。當成功取得 nVideoWidth 與 nVideoHeight 後,我們利用 malloc 來配置 NV12 所需的記憶體大小(長 × 寬 × 1.5 倍):
核心 API 與結構體介紹
記憶體準備好之後,我們終於要把底層的解碼畫面給拿出來了!但在這之前,我們必須先釐清一個極度重要的核心觀念。
➤ 核心觀念解析:為什麼我們需要「手動解開結構體」?
如果您有跟著我們完成第 10 章的教學,您可能會好奇:「 之前我們做純播放或錄影時,不是只要把接收到的參數直接塞給下一個 API 就好了嗎?為什麼現在要這麼大費周章地複製記憶體?」
這背後其實有著兩個關鍵的考量:
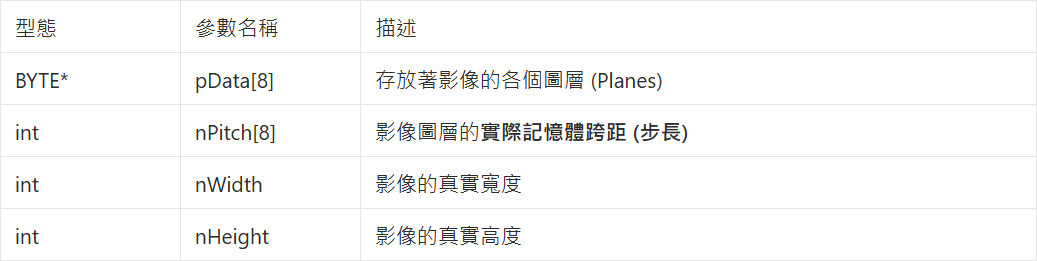
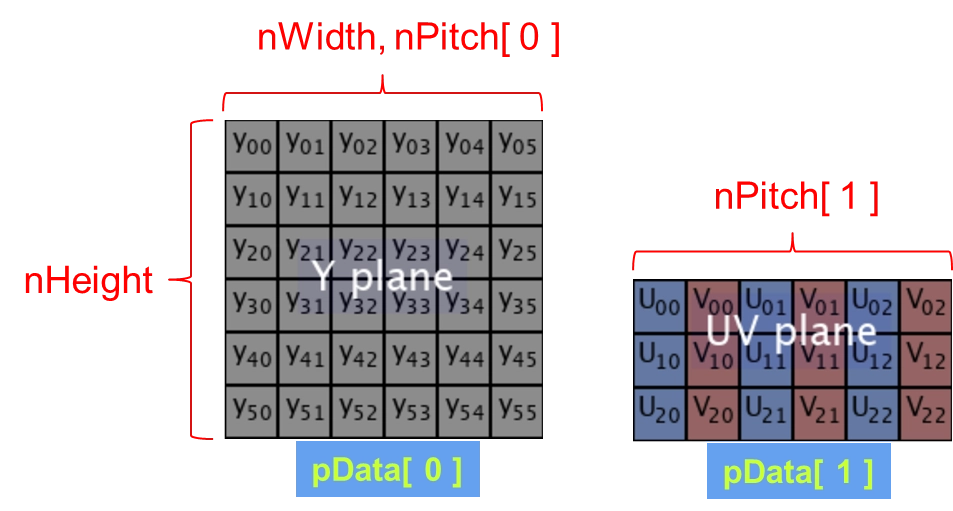
1. 確保 AI 與 OpenCV 接收到純淨的 RAW Data ( 原始數據 ) :AI 引擎 ( QDEEP ) 與 OpenCV,它們只認得「 純淨、排列緊密、毫無雜質的 RAW Data 」!在底層架構中,當解碼器把畫面丟出來時,這些數據是被包裹在一個名為 qcap_av_frame_t 的專屬結構體裡面的。此外,因為 GPU 與硬體在處理影像時有所謂的「 記憶體對齊 ( Memory Alignment ) 」機制,這會導致影像在記憶體中的實際跨距( nPitch 或 Stride),往往會大於影像真正的寬度( nWidth )。如果我們不解開結構體並剔除多餘的邊緣空白,畫面就會發生嚴重的扭曲。
2. 底層記憶體的安全保護機制 :將資料包裹在結構體中,並要求開發者必須透過 API( 上鎖 ➔ 複製 ➔ 解鎖 )來取用,是為了保護裸數據不被使用者直接觸碰。在 C/C++ 開發中,若直接開放底層指標,開發者很容易在處理影像時不小心發生「 越界修改 」的情況。透過這層保護機制,能確保底層程式運行所需要的記憶體空間不容易被外部誤改,不僅讓系統運作更加安全,也大幅降低了程式崩潰 (Crash) 的風險。
為了把純淨的影像安全地拿出來,我們需要依序呼叫以下三個 API,並了解 qcap_av_frame_t 的內部構造 :
QCAP_BUFFER_GET_RCBUFFER ( 取得緩衝區 )
用來從 Callback 的原始數據中,取得底層影像結構體的 Handle。

QCAP_RCBUFFER_LOCK_DATA ( 上鎖並解開結構體 )
取得 Handle 後,我們必須將其「上鎖」以避免複製到一半時資料被底層覆寫。成功上鎖後,它會回傳 qcap_av_frame_t 結構體!

認識 qcap_av_frame_t 結構體: 當我們拿到這個結構體後,裡面包含了四個極度重要的影像資訊:
QCAP_RCBUFFER_UNLOCK_DATA ( 解鎖並釋放 )
當我們利用 memcpy 把 qcap_av_frame_t 裡面的資料安全地複製到我們自己的記憶體後,絕對不能忘記呼叫這個 API 來解鎖,把資源還給底層,否則系統會立刻卡死!

如果我們不解開結構體,直接把整包記憶體丟給 AI 或 OpenCV,多出來的那些「 無效填充邊距 ( Padding ) 」就會導致畫面嚴重扭曲( 例如 : 出現綠色、紫色的斜斜條紋 )。
因此,在這個步驟中,我們的神聖任務就是:把結構體打開,剝除所有多餘的 Padding,將純淨的 Y Plane ( 明暗 ) 與 UV Plane ( 色彩 ) 提取出來,緊密地排列進我們剛剛配置好的 NV12 緩衝區中 !
提取 NV12 與 OpenCV 影像轉換渲染
在 mainwindow.cpp 引入 OpenCV
在開始撰寫影像轉換邏輯之前,請務必先回到 mainwindow.cpp 的最上方,引入 OpenCV 的核心標頭檔:
鎖定 Buffer 並提取 NV12 原始影像
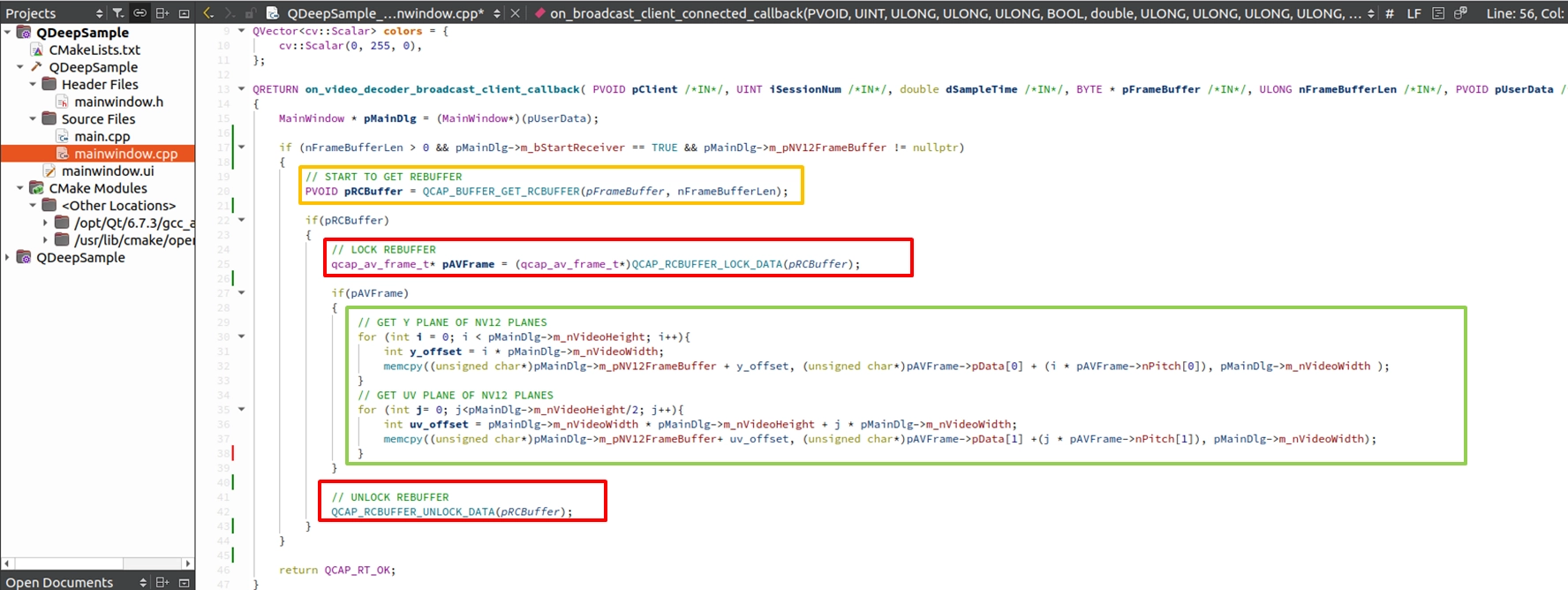
現在,讓我們把剛剛學到的 API 組合起來!請到 on_video_decoder_broadcast_client_callback 總機中。 要安全地把畫面拿出來,實作這段「取得 Buffer ➔ 上鎖 ➔ 複製 ➔ 解鎖」的嚴謹流程:
1. 呼叫 QCAP_BUFFER_GET_RCBUFFER 取得影像結構體。
2. 呼叫 QCAP_RCBUFFER_LOCK_DATA 將資料上鎖(防止在我們複製到一半時,資料被底層覆寫)。
3. NV12 格式分為 Y Plane ( 明暗 ) 與 UV Plane ( 色彩 ) 兩個平面。我們利用迴圈與 memcpy ,分別從 pData (Y) 與 pData 中,配合其步長 (nPitch) 將資料複製到我們準備好的 m_pNV12FrameBuffer 裡。
4. 完成後,呼叫 QCAP_RCBUFFER_UNLOCK_DATA 解鎖。
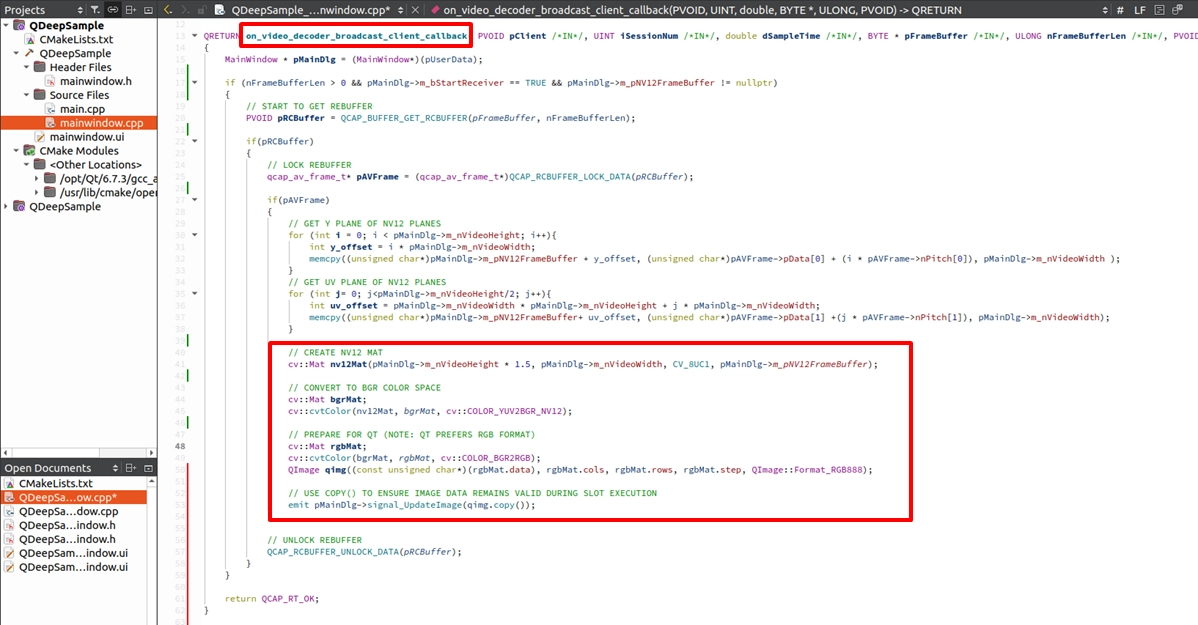
轉換為 cv::Mat 並跨執行緒發送影像訊號
接著,請到 on_video_decoder_broadcast_client_callback 總機中,遵循「取得 Buffer ➔ 上鎖 ➔ 複製 ➔ 解鎖」的流程把 NV12 複製出來。然後,立刻利用我們剛剛引入的 OpenCV 將其轉換為 RGB 格式的 QImage,最後透過 emit 將影像跨執行緒發送出去:
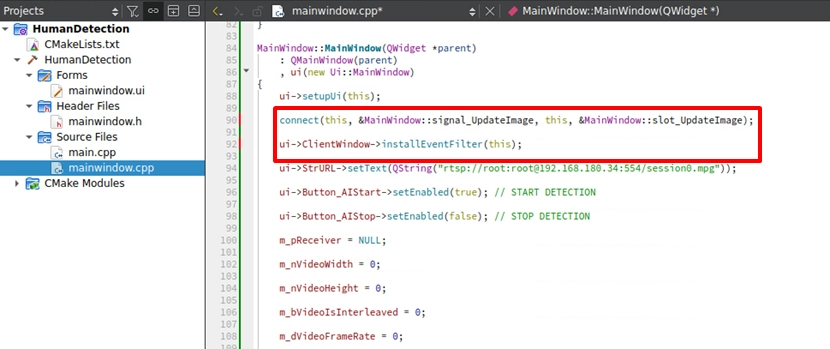
在建構子啟動跨執行緒渲染機制
剛剛我們把訊號 emit 出去了,但 UI 介面怎麼知道要接收呢? 請回到 mainwindow.cpp 的 建構子 MainWindow::MainWindow(...) 內。我們必須在這裡進行「訊號綁定」與「安裝事件過濾器」,這兩行是畫面能顯示的絕對關鍵:
實作影像暫存與觸發重繪
接著在 mainwindow.cpp 的底部,實作我們剛剛綁定的 slot_UpdateImage 。這個槽函式的工作很簡單:把傳過來的最新圖片存起來,然後大喊一聲「 請畫布更新!」:
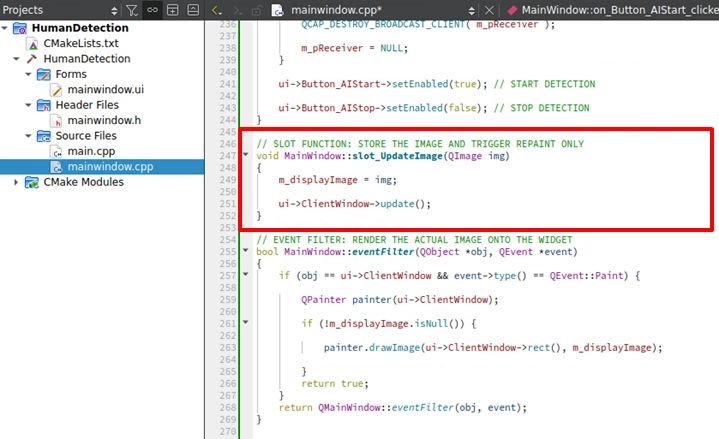
利用 QPainter 渲染畫面
最後一步!實作 eventFilter 事件過濾器。當剛才的 update() 觸發了 ClientWindow 的 Paint (繪圖) 事件時,我們就立刻攔截下來,並親手用 QPainter 把 m_displayImage 畫到視窗上:
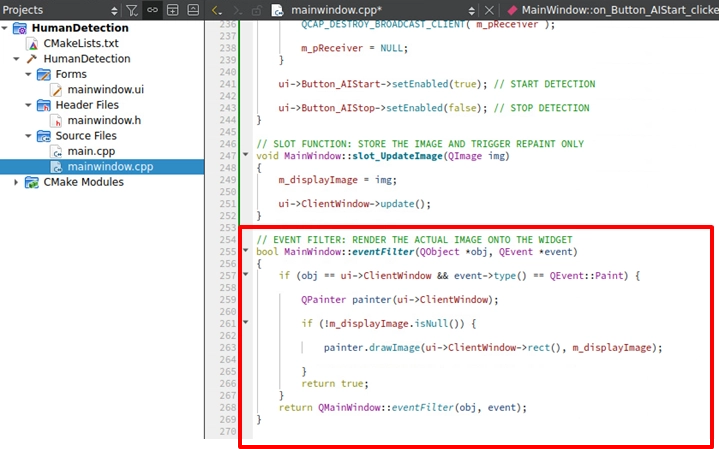
最終驗證
太棒了!到這裡為止,我們的 QDeepSample 基礎樣板已經完美建立。現在,請按下 「Build and RUN」 執行這個專案。貼上您的 RTSP 網址並點擊 START RECEIVER,您將會看到攝影機的流暢畫面已經透過您親手寫的 Qt 與 OpenCV 繪圖機制,完美顯示在軟體視窗中了!
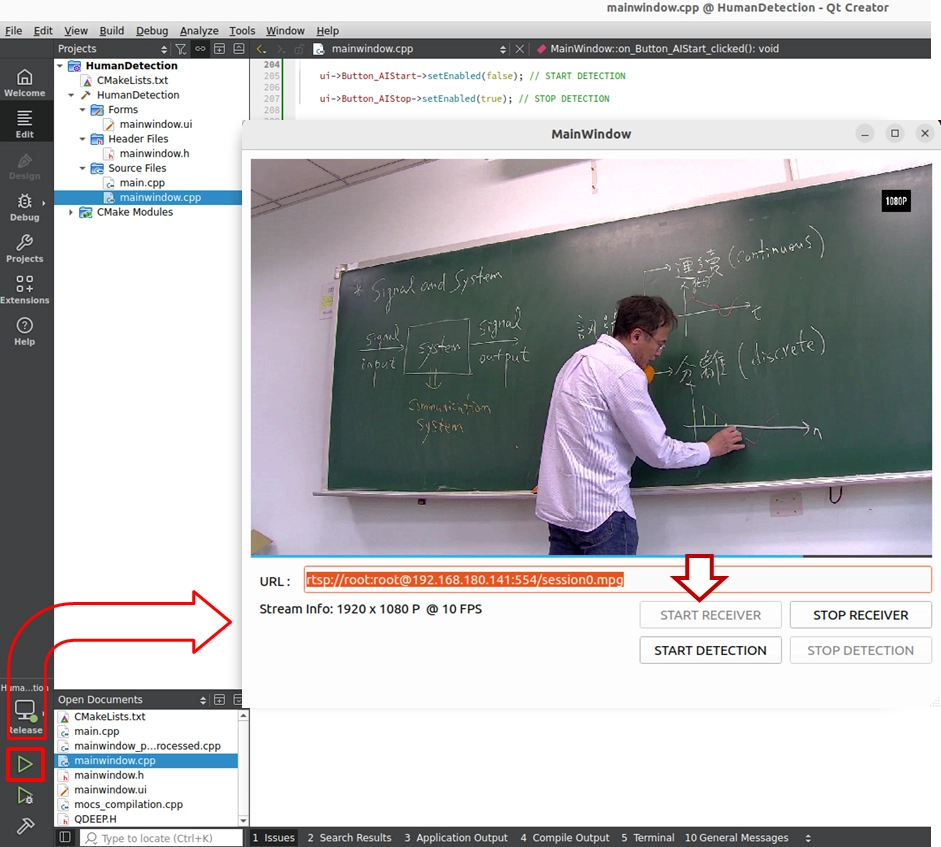
眼尖的您一定發現了,我們介面上的 START DETECTION 與 STOP DETECTION 按鈕目前點下去還是灰色的,沒有任何反應——別著急,您手上的這套 QDeepSample 專案,現在已經具備了「純淨 NV12 影像提取能力」與「自訂畫布渲染能力」。在下一章實作中,我們將會真正地喚醒 QDEEP 引擎,只需把這包準備好的 NV12 影像餵給它,再把 AI 回傳的座標用 OpenCV 畫成方框,您的軟體就能瞬間獲得看懂畫面的超能力!我們下一章見!