10-13 人物虛擬背景功能範例教學
歡迎進入影像分割的另外一個應用——虛擬背景替換 ! 本章節我們將沿用上一章的影像分割大腦,但這次我們要解鎖一支「進階版 」的 Custom API。您將學會如何把外部的圖片化為數據流,直接注入到 AI 引擎中,讓 AI 幫您完成完美的綠幕級去背合成!
學習目標
透過本章節,您將學會:
1. 認識進階屬性 API (_EX) : 從傳遞單一數值 (浮點數),升級為將「整張背景圖片的陣列數據」傳入底層。
2. 掌握虛擬背景的解析度限制 : 實作 OpenCV 影像縮放 (cv::resize) ,滿足底層引擎對 1920×1080 尺寸的嚴格要求。
準備工作
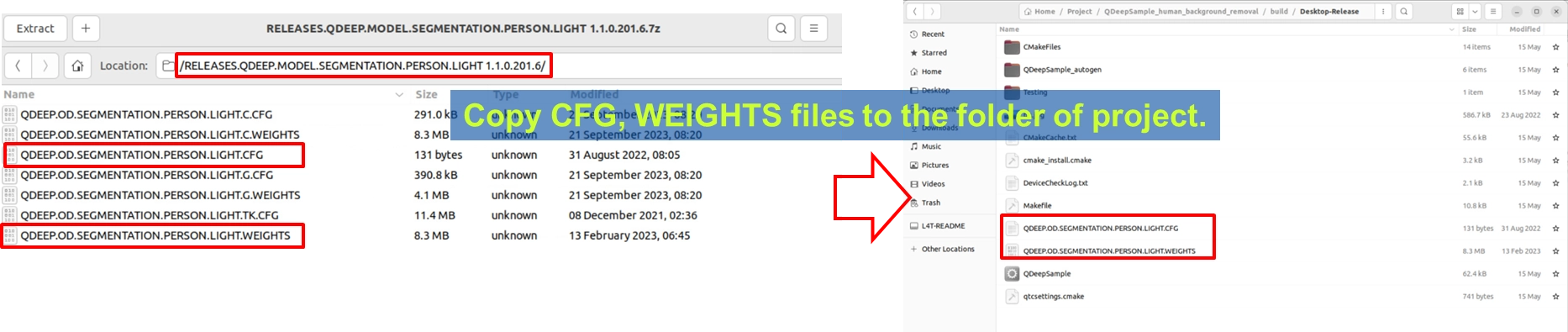
由於「背景模糊」與「背景替換」在底層都是依賴「找出人物輪廓 ( Segmentation )」的技術,因此模型檔案是完全共用的! 請確認您的專案建置輸出目錄下,已經擁有與上一章相同的檔案 QDEEP.OD.SEGMENTATION.PERSON.LIGHT.CFG 與其權重檔。
核心 API 要怎麼改?
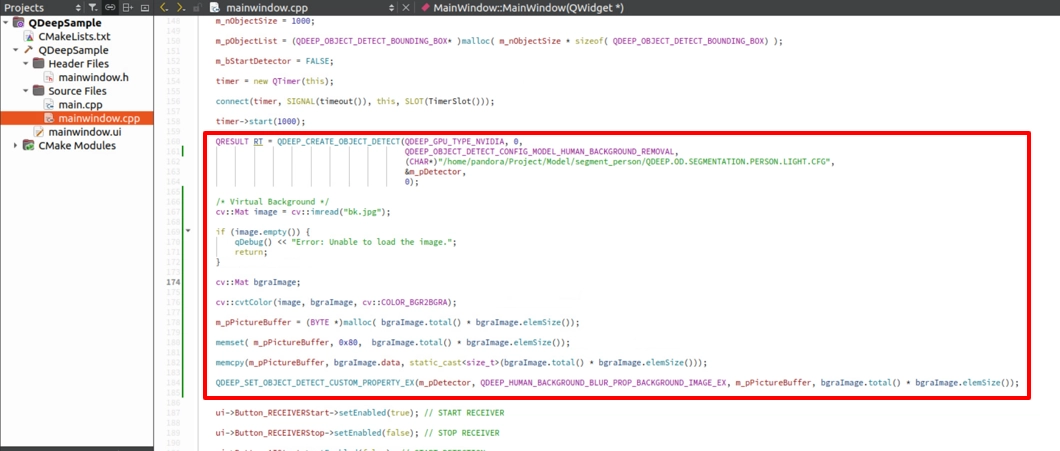
請開啟您的專案,改變模型配置類型,在 QDEEP_CREATE_OBJECT_DETECT 中,請將 Enum 換成 QDEEP_OBJECT_DETECT_CONFIG_MODEL_HUMAN_BACKGROUND_REMOVAL。
QDEEP_CREATE_OBJECT_DETECT
這是建立 AI 引擎並載入大腦(模型)的最關鍵 API。使用者必須透過此 API 初始化偵測器。

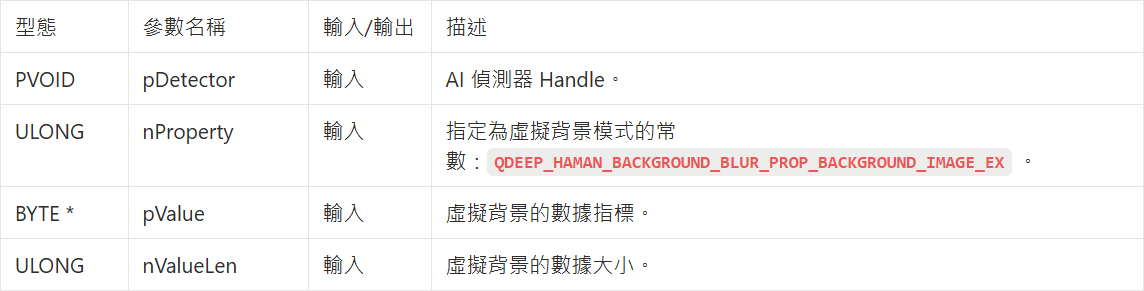
QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY_EX
在 10-12 中,我們使用 QDEEP_SET_OBJECT_DETECT_CUSTOM_PROPERTY 傳入一個 0~100 的 float 來控制模糊強度。 但這次,我們要傳給 AI 的是「一張圖」!因為圖片包含了龐大的陣列數據,我們必須改用它的 擴充版 API :
➤ 請注意,目前虛擬背景圖片僅支援 1920×1080!
QDEEP_OBJECT_DETECT_BOUNDING_BOX 結構體
AI 引擎會在這個結構體中透過 pImageResultBuffer 參數將算好的高畫質影像像素(BGRA 格式)直接倒進這塊記憶體中供我們提取!

撰寫核心程式碼
請開啟您的專案,我們將 10-12 的程式碼進行關鍵的微調:
模型載入、載入外部圖片並呼叫 _EX API
在建構子 MainWindow::MainWindow(...) 中,換上虛擬背景專屬的模型設定 QDEEP_OBJECT_DETECT_CONFIG_MODEL_HUMAN_BACKGROUND_REMOVAL。在建構子中建立好偵測器後,請移除上一章的模糊 API,替換為以下的「讀圖、縮放、注入」標準 S.O.P:
首先需要先宣告記憶體以及解構子中安全釋放影像記憶體:
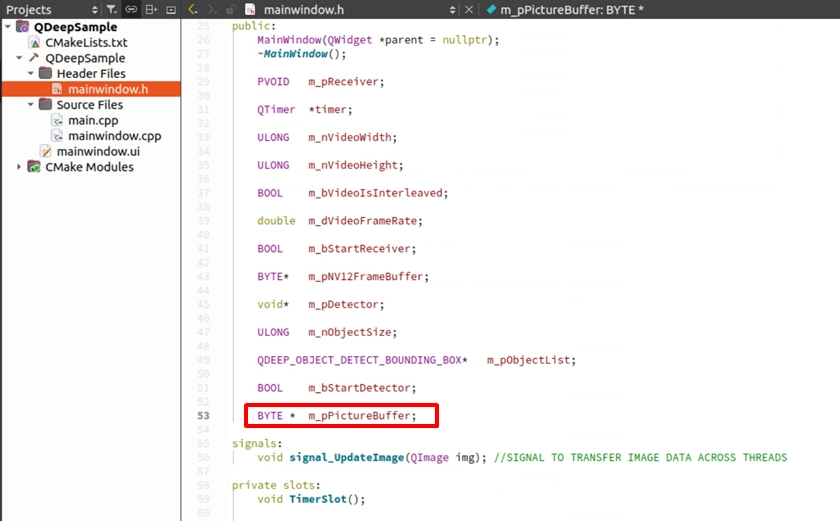
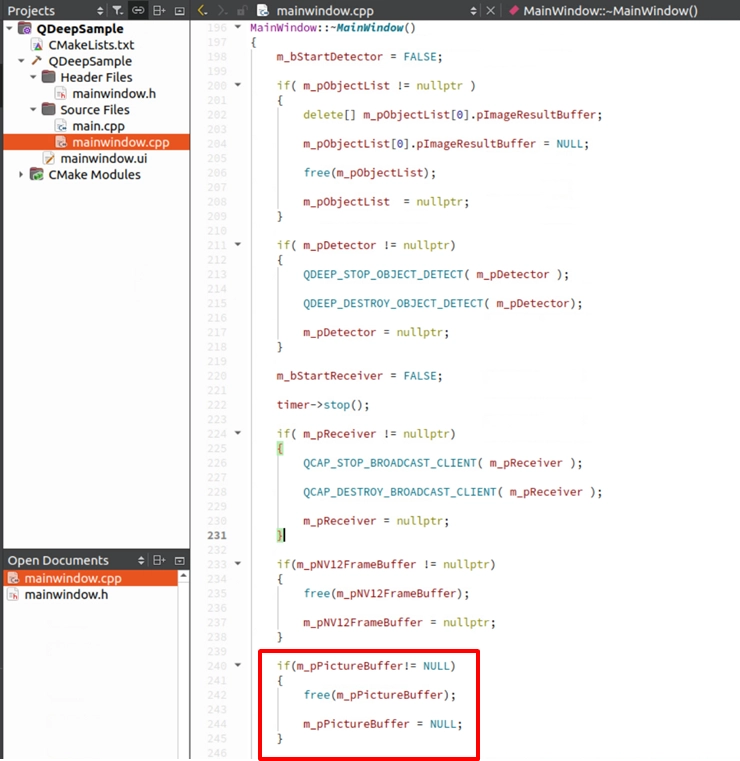
再利用 malloc 為我們剛剛在標頭檔宣告的 m_pPictureBuffer 配置記憶體,所需大小為 bgraImage.total() * bgraImage.elemSize() 。接著使用 memset 初始化,並透過 memcpy 將轉換後的 OpenCV 影像數據安全地複製進這個緩衝區中。
沿用 10-12 的 ImageBuffer 處理架構
接下來的事情就非常輕鬆了!由於底層同樣是產出一張處理好的 BGRA 高畫質圖片,我們完全不需要修改連線成功時的 Buffer 宣告,以及 OpenCV 畫圖替換的邏輯。
最終驗證
請按下左下角的 「Build and RUN」 執行專案:
1. 請在專案的執行目錄下,準備一張您喜歡的風景圖片,並命名為 bk.jpg.
2. 按下左下角的 「Build and RUN」執行專案。
3. 啟動接收與偵測。
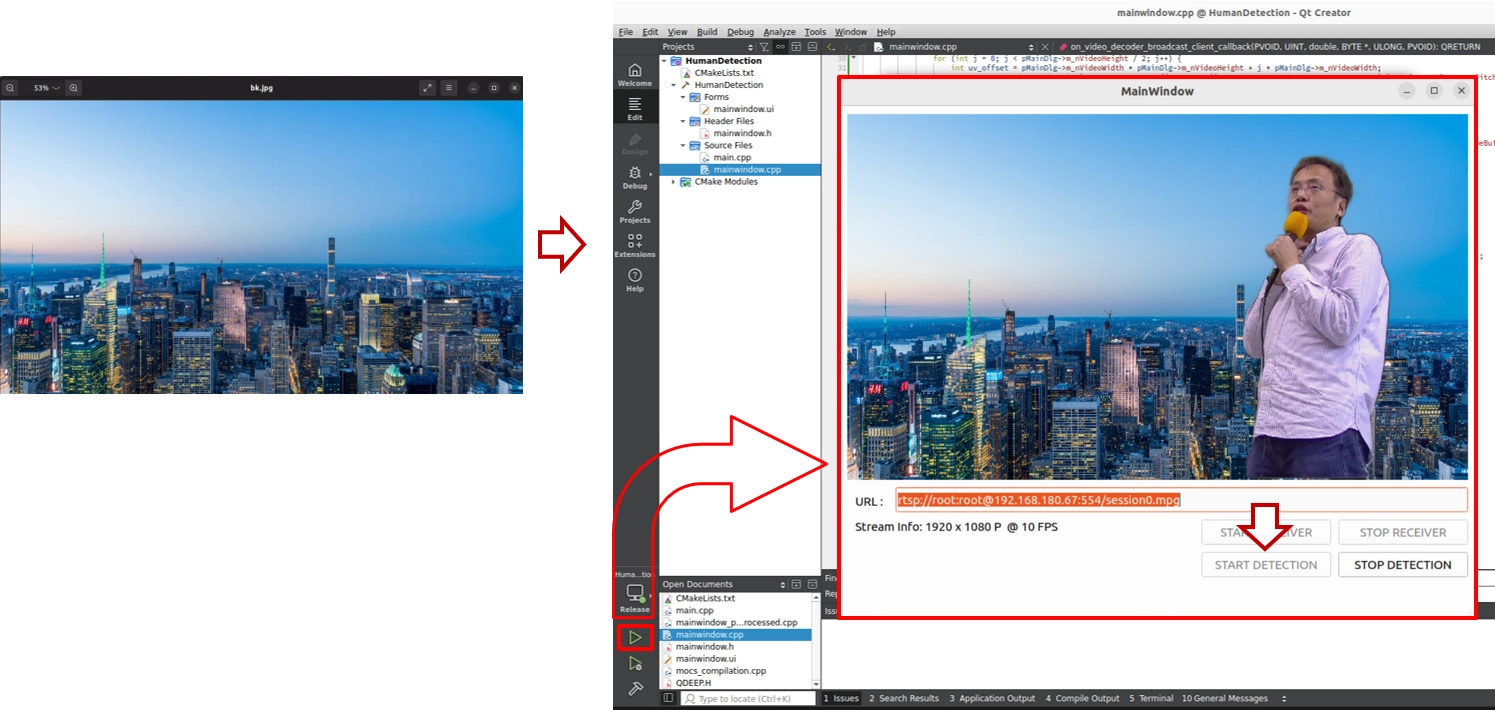
當您走進鏡頭時,您會發現自己猶如身處新聞播報台或好萊塢的綠幕攝影棚!原本背後雜亂的辦公室已經完全消失,取而代之的是您剛剛注入的那張 bk.jpg 風景照,而且邊緣去背的效果極度平滑自然!