10-3 人形偵測功能範例教學
學習目標
在上一章節中,我們已經成功打造出一個具備「網路串流接收」與「OpenCV 影像轉換渲染」能力的純淨基礎樣板。本章節將帶領讀者在這個堅實的基礎上,正式喚醒 NexVDO SDK 的 QDEEP AI 引擎。
透過本章節,您將學會:
1. 如何正確配置與載入 AI 預訓練模型檔案。
2. 掌握 QDEEP 引擎中「物件偵測 (Object Detection)」系列的核心 API。
3. 將接收到的純淨 NV12 無壓縮影像,完美餵入 AI 引擎進行推論。
4. 解析 AI 回傳的元數據 (Metadata),並透過 OpenCV 將辨識結果(如:追蹤框與標籤)疊加繪製於即時畫面上。
準備工作
在召喚 AI 引擎之前,我們必須先準備好經過訓練的模型檔案。
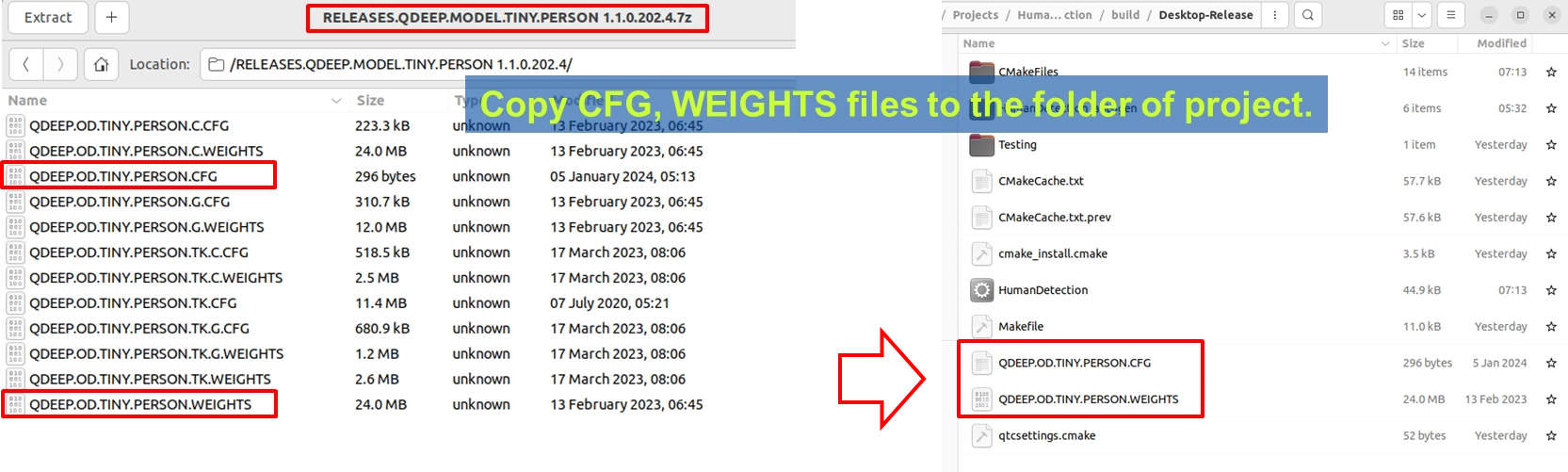
1. 準備好聰泰提供的 Tiny Person 人形偵測模型壓縮檔 (RELEASES.QDEEP.MODEL.TINY.PERSON...)。
2. 將解壓縮後的 QDEEP.OD.TINY.PERSON.CFG ( 設定檔 ) 與 QDEEP.OD.TINY.PERSON.WEIGHTS ( 權重檔 ) 複製出來。
3. 將這兩個檔案,直接貼上到您 Qt 專案的 建置輸出目錄 下(通常是 build-xxx-Desktop-Release 資料夾內,與執行檔放在同一層)。
核心 API 與結構體介紹
要啟動 QDEEP 物件偵測引擎,我們同樣需要將「取得影像」與「處理影像」分為兩個階段。我們將在 Callback 中取得原始無壓縮的資料 ( NV12 ),然後把它「餵」給 QDEEP 引擎去處理。

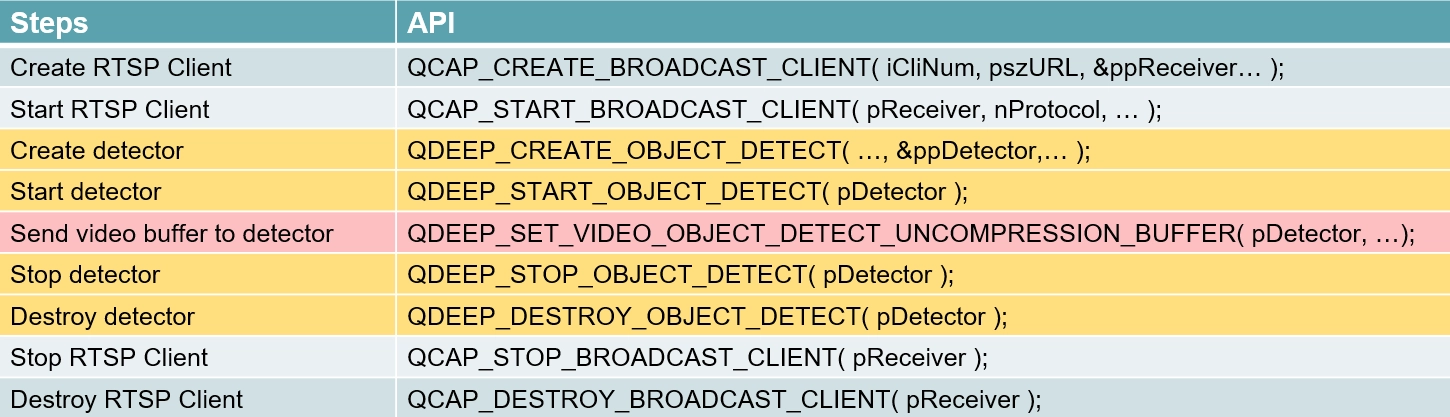
確認模型檔案就位後,標準的 API 使用順序如下:
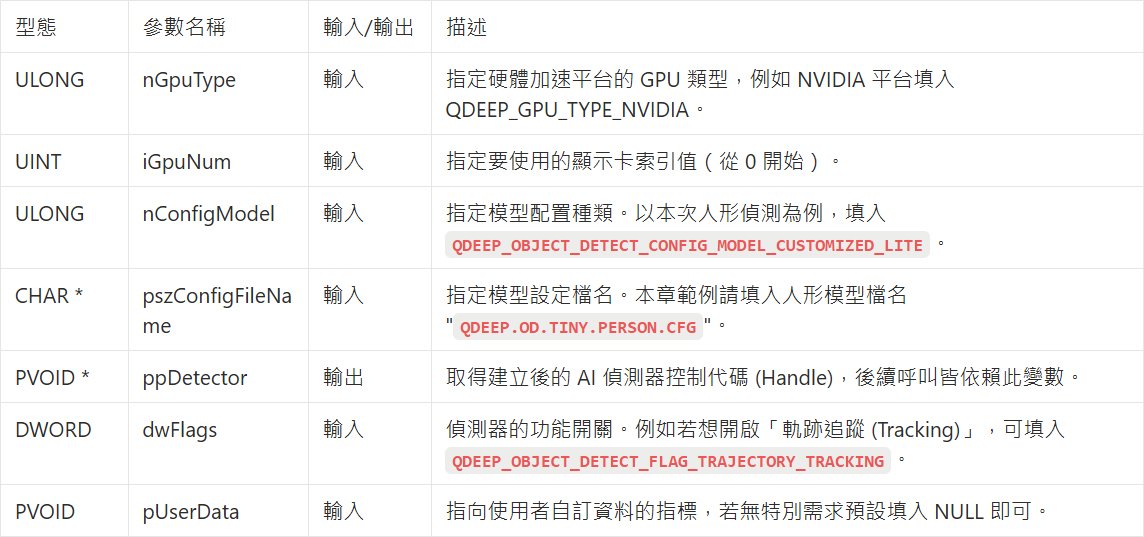
1. QDEEP_CREATE_OBJECT_DETECT : 建立 AI 偵測器(並指定要載入的模型檔案)。
2. QDEEP_START_OBJECT_DETECT : 啟動 AI 偵測引擎。
3. QDEEP_SET_VIDEO_OBJECT_DETECT_UNCOMPRESSION_BUFFER : 在 Callback 中持續餵入影像無壓縮 Buffer,讓 AI 進行辨識推論。
4. QDEEP_STOP_OBJECT_DETECT : 停止 AI 偵測引擎。
5. QDEEP_DESTROY_OBJECT_DETECT : 銷毀 AI 偵測器並安全釋放資源。
QDEEP_CREATE_OBJECT_DETECT
這是建立 AI 引擎並載入大腦(模型)的最關鍵 API。使用者必須透過此 API 初始化偵測器。
QDEEP_START_OBJECT_DETECT
當模型載入完成後,透過此 API 正式啟動 AI 引擎的推論功能。

QDEEP_SET_VIDEO_OBJECT_DETECT_UNCOMPRESSION_BUFFER
我們需要在 Callback 中,源源不絕地將解開結構體後的純淨 NV12 影像餵給這支 API,並從它手中拿回 AI 的辨識結果。

QDEEP_STOP_OBJECT_DETECT
用此 API 暫停 AI 引擎的運算。

QDEEP_DESTROY_OBJECT_DETECT
在程式完全關閉前,務必呼叫此 API 來銷毀 AI 偵測器,安全釋放 GPU 顯示記憶體與系統資源。

➤ 認識 QDEEP_OBJECT_DETECT_BOUNDING_BOX 結構體
當 AI 分析完成後,回傳的 pObjectList 陣列中,每一個元素都包含了一個物件的完整資訊:


撰寫核心程式碼
有了觀念後,請開啟您的 QDeepSample 專案,我們準備將 AI 的靈魂注入程式中!
新增標頭檔變數與初始化
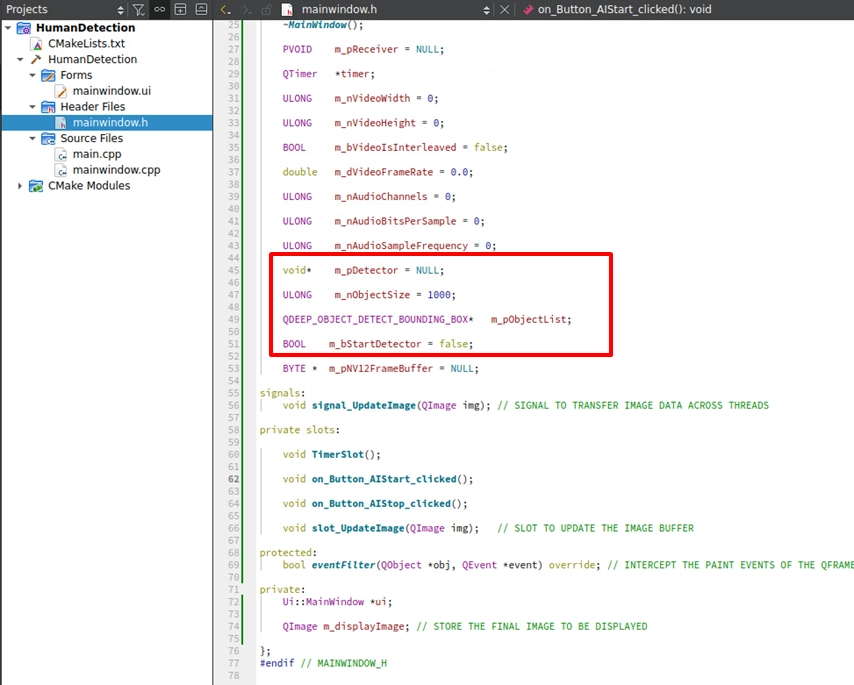
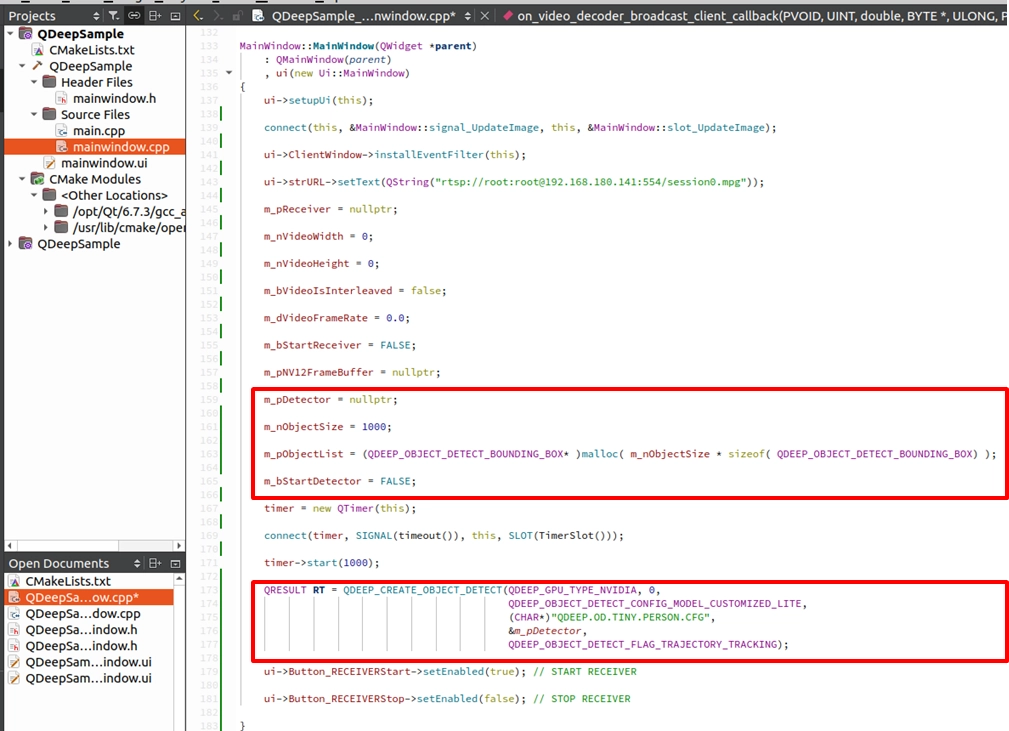
開啟 mainwindow.h,在 private: 變數區宣告 AI 引擎的 Handle、裝載結果的結構體陣列,以及控制開關的布林值:
接著開啟 mainwindow.cpp 的建構子 MainWindow::MainWindow(...) ,我們需要用 malloc 為結果陣列配置記憶體,並呼叫 API 來正式建立 AI 引擎。
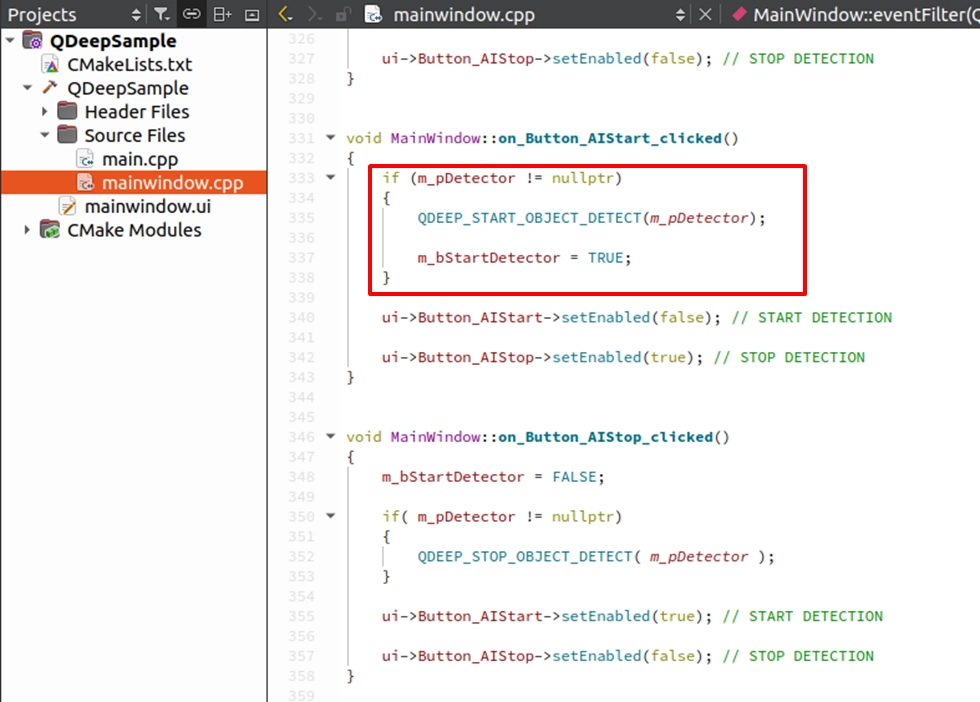
實作 START DETECTION ( 啟動偵測 )
找到我們在上一章佈置好的 on_Button_AIStart_clicked() 槽函式。填入啟動引擎的 API,並連動按鈕狀態:
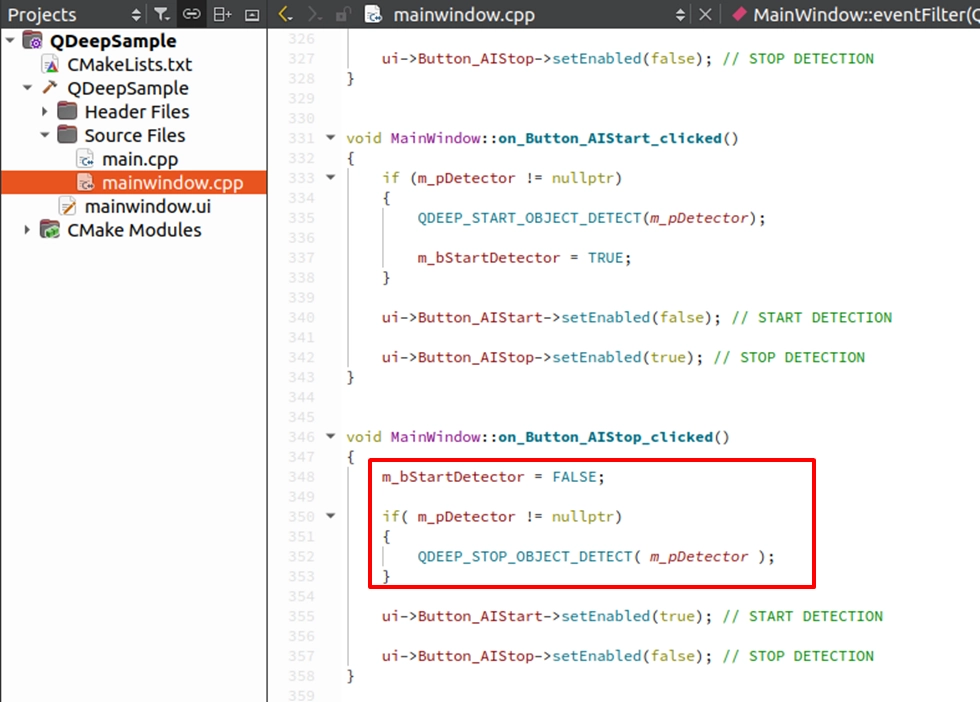
實作 STOP DETECTION ( 停止偵測 )
找到我們在上一章佈置好的 on_Button_AIStop_clicked() 槽函式。填入停止引擎的 API,並連動按鈕狀態:
餵入 NV12 數據並利用 OpenCV 畫出辨識結果
請來到 on_video_decoder_broadcast_client_callback 回呼函式中。 在我們上一章寫好的 OpenCV 影像轉換邏輯 (cv::cvtColor) 的正下方。這裡我們將分為三個重要階段來解說:
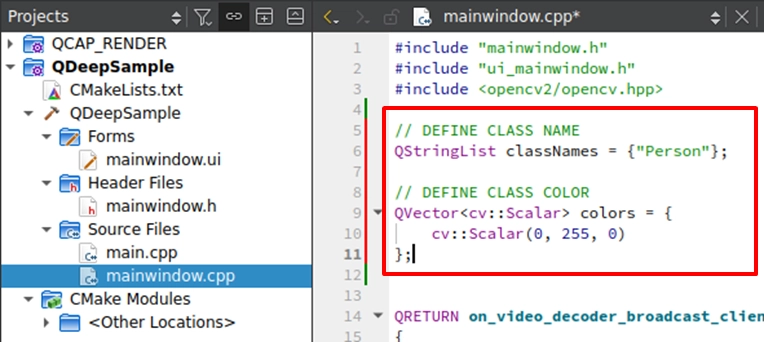
階段一、建立多類別的「標籤與專屬色彩」對應表 :在畫圖之前,我們先在程式碼宣告兩個陣列 :
classNames ( 裝載名稱 ) 與 colors ( 裝載顏色 )。
➤ 為什麼要用陣列? 因為 AI 回傳的結果中,會有一個 nClassID ( 類別索引 )。我們可以利用這個 ID 直接去陣列裡面找對應的名字與顏色!雖然本章節範例的人形模型只會回傳 0 ( 表示 Person ),但這樣的架構具備極高的擴充性。未來如果是多類別模型,只要在這個陣列中擴充定義(例如 : 給 ID:1 設定紅色、ID:2 設定藍色),就能輕鬆實現「不同物件畫不同顏色框」的進階視覺效果!
階段二、發送 NV12 影像給 AI 引擎:在我們透過前面的步驟取得 NV12 影像緩衝區 (Buffer) 後,就可以將它發送給偵測器 (Detector) 了。
➤ 極度重要的細節 : 在把資料餵給 AI 引擎之前,我們「必須先重置物件列表的容量大小 (pMainDlg->m_nObjectSize = 1000)」! 因為 m_nObjectSize 是一個輸入/輸出 (I/O) 共用的參數。傳入時代表「我們準備的最大陣列容量」,執行後會被 API 修改為「該畫面實際偵測到的物件數量」。如果不重置它,這個數值就會越變越小(例如 : 上一張畫面只偵測到 2 個人,容量就會被改為 2),導致後續畫面無法容納新的物件而發生錯誤。
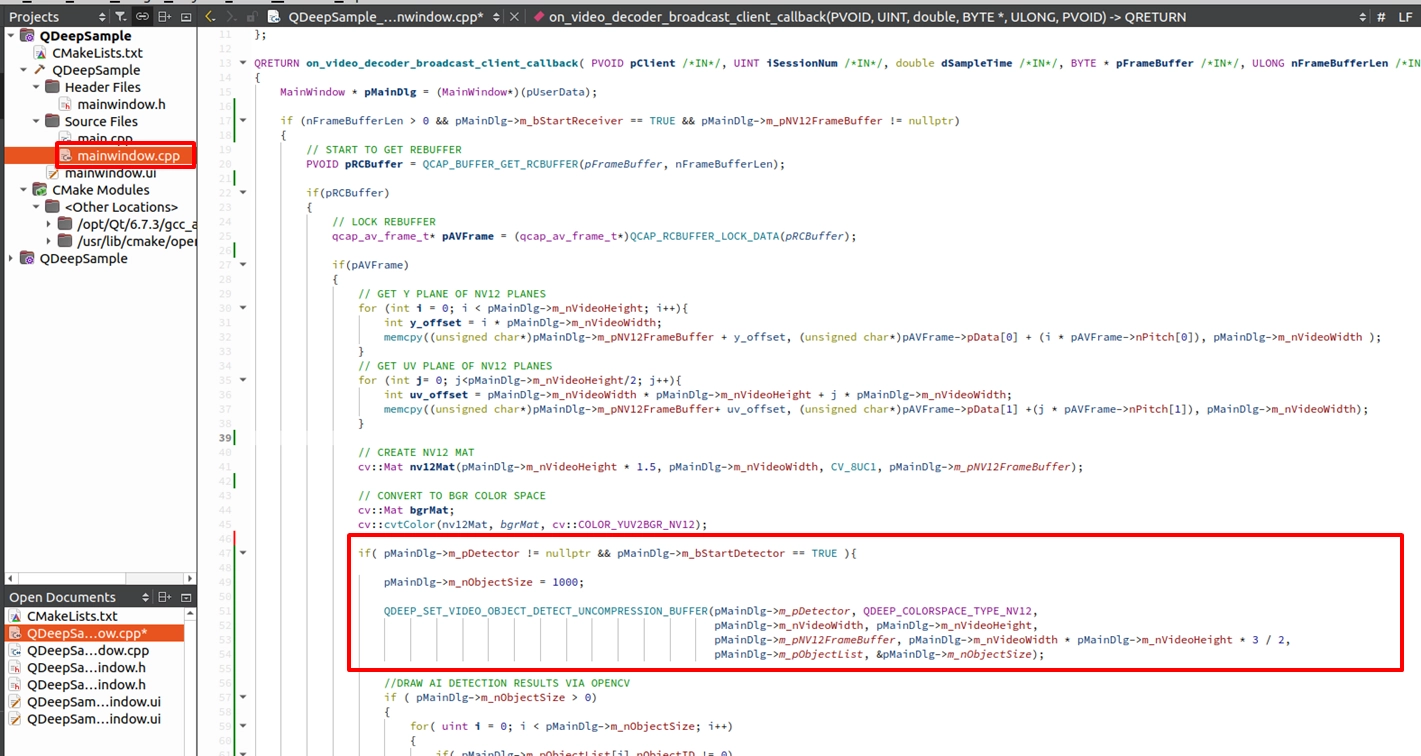
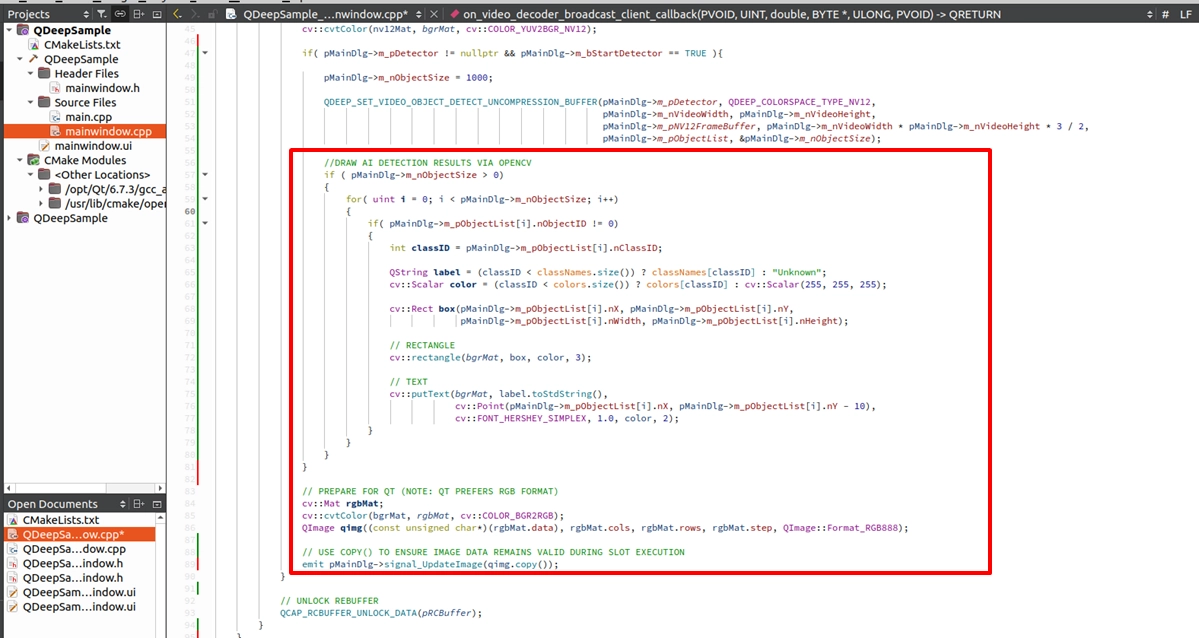
階段三、解析多個物件位置並疊加文字與辨識框:當我們從 API 取得物件的資訊後,就可以使用 OpenCV 的繪圖 API 將這些物件精準標記出來。 面對畫面上可能同時出現的多個物件,我們必須利用迴圈 ( for-loop ) 來走訪 m_pObjectList ,逐一取得每個物件的位置。接著,我們不僅要在畫面上畫出矩形追蹤框,更要在物件的頂端疊加文字,清楚標示出該物件的標籤與其專屬的追蹤 ID !
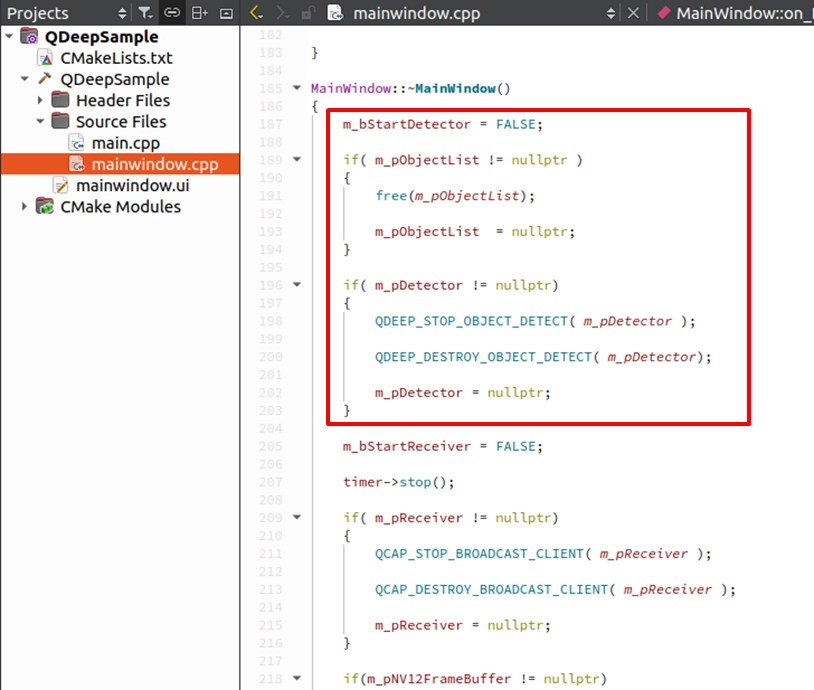
程式關閉前的安全下車
最後,請在解構子 ~MainWindow() 中,補上釋放 AI 模型資源的 API 與 free 記憶體的動作。這能確保在關閉視窗時不殘留任何 GPU 負載。
最終驗證
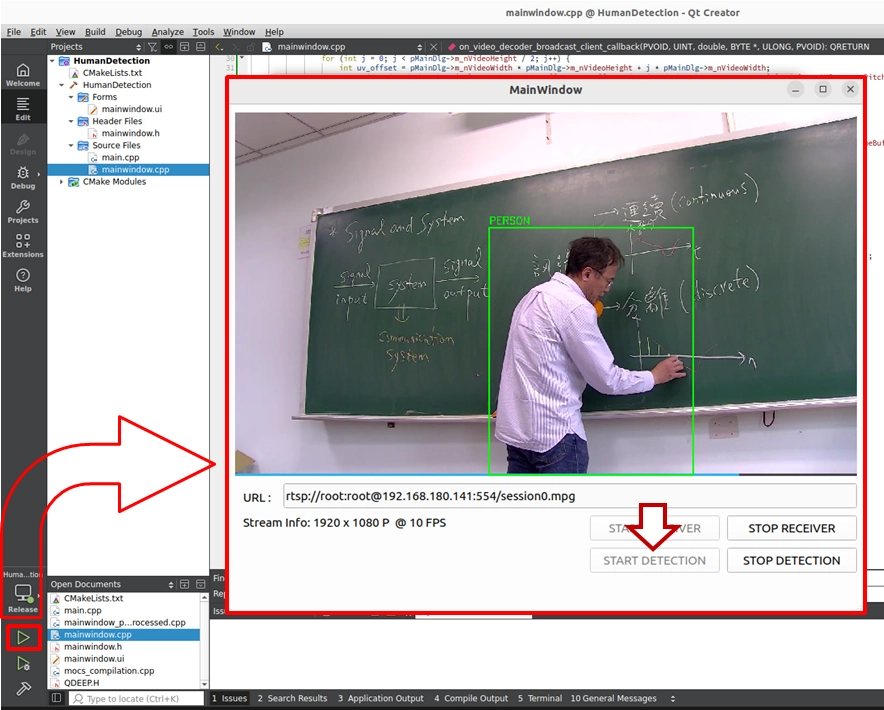
恭喜您!您已經成功完成了第一個具備物件偵測 ( Object Detection ) 功能的 AI 視覺分析專案!現在,請按下左下角的 「 Build and RUN 」 執行專案,並跟著我們一起見證奇蹟的時刻。
在軟體介面上,您會看到我們精心佈置的四顆按鈕,請依照順序進行操作:
1. START RECEIVER ( 啟動接收 ):點擊後將啟動網路串流,此時畫面上會顯示純淨、尚未經過 AI 處理的即時影像。
2. START DETECTION ( 啟動偵測 ):確認畫面順暢後,點擊此按鈕來啟動 AI 分析,這時程式會正式喚醒 QDEEP 引擎!
當您點擊 START DETECTION 後,只要畫面中出現人物,系統就會以極高的精準度,用綠色的追蹤框將他鎖定,並在上方完美疊加出「 Person 」字樣!
➤ 溫馨小叮嚀 ( 非常重要 ) :在您第一次開啟這支軟體 ( 執行程式 ) 的瞬間,介面可能會需要稍等一下才會顯示出來,請不要緊張!這是因為我們將「 載入 AI 模型 」的邏輯寫在了程式的建構子內。模型在首次執行時必須進行初始化配置,此時系統正努力將龐大的神經網路權重檔載入到 GPU 中。只要軟體成功開啟( 首次載入完成 ),代表 AI 大腦已經在背景準備就緒!後續當您再次開啟軟體時,就不需要這個初始化的等待時間了!
3. STOP DETECTION ( 停止偵測 ) :當您想關閉 AI 時點擊此按鈕,畫面會立刻恢復為無辨識框的純影像。
4. STOP RECEIVER ( 停止接收 ) :結束測試,停止網路串流。
在下一章 【10-4】 中,我們將會向您展示這個架構有多麼強大——我們甚至不需要更動核心程式碼,只需要替換掉「模型檔案 ( CFG/WEIGHTS )」並擴充上一段宣告的「顏色與標籤陣列」,就能讓這支程式瞬間進化為「人臉、頭部、身體多物件辨識系統」!我們下一章見!