10-8 万物検出機能サンプルチュートリアル
これまでの章を通して、さまざまな専用 AI モデルをスムーズに切り替えられるようになりました。では、もしお客様から「画面内の『リュック』や『水筒』を検出したい」という特殊な要望があり、公式からその専用モデルが提供されていない場合はどうすればよいでしょうか?
本章では、GenAI 万物検出 ( Everything Detection ) を解説します!これは「意味理解」能力を備えた AI モデルです。従来の物体検出との最大の違いは、 モデルを再学習する必要がなく、API で「テキスト ( Text )」を渡すだけで、AI がその文字説明に合う物体を画面内で自動的に検出して枠で囲んでくれるという点です。
学習目標
本章では、以下を学びます。
1. より複雑な構成を持つ GenAI モデルファイルを理解し、読み込む方法。
2. UI を変更せず、10-3 のプロジェクト構成をそのまま再利用する方法。
➤ 人物検出モデルはこちらで復習できます : 10-3 人物検出機能サンプルチュートリアル
3. 新しい Prompt API QDEEP_SET_OBJECT_DETECT_CUSTOM_SEARCH_TEXT を使い、ソフトウェアにゼロショット学習能力を持たせる方法。
準備作業
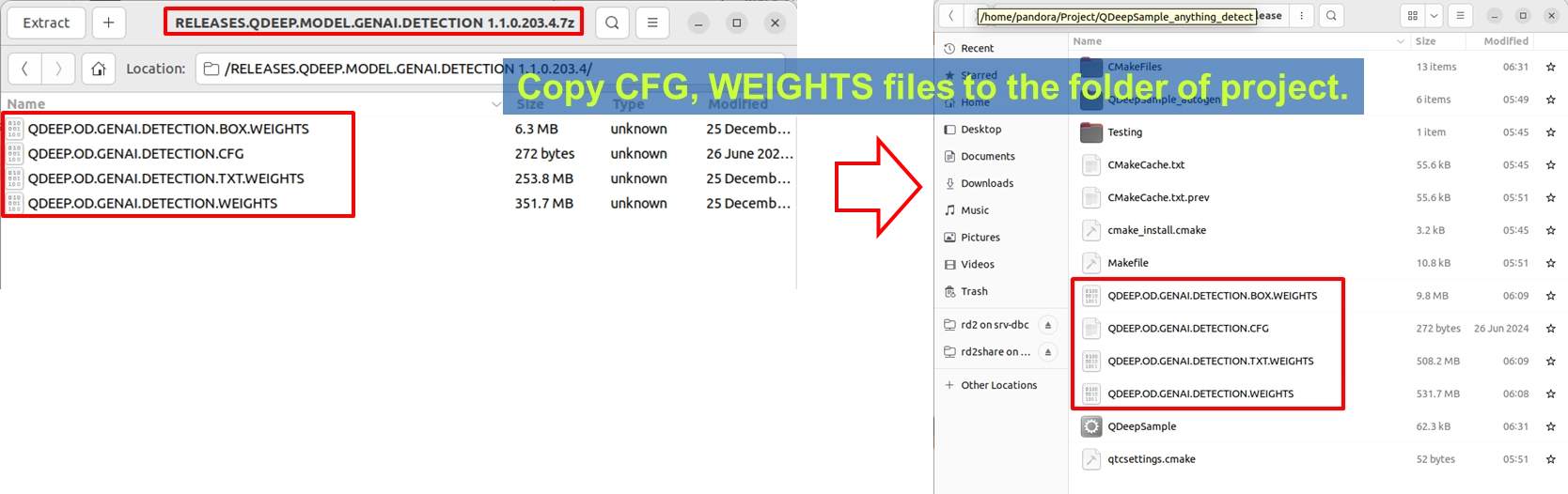
今回のモデルパッケージは、これまでのものと少し異なります。画像認識と意味認識を組み合わせているため、ファイル数が多くなっています。
1. YUAN から提供された GENAI.DETECTION モデル圧縮ファイルを解凍します。
2. 中には 4 つ の重要なファイルがあります。
• QDEEP.OD.GENAI.DETECTION.CFG
• QDEEP.OD.GENAI.DETECTION.WEIGHTS
• QDEEP.OD.GENAI.DETECTION.TXT.WEIGHTS
• QDEEP.OD.GENAI.DETECTION.BOX.WEIGHTS
3. 必ずこの 4 つのファイルをすべてコピ ーし、Qt プロジェクトの ビルド出力ディレクトリ に貼り付けてください。どれか 1 つでも欠けると、AI は人間の文字を理解できません。
コア API はどのように変更するのか?
今回は UI をまったく変更する必要はありません。コード内の「重要な 5 つの API」に注目し、新しい API を 1 つ追加するだけです。
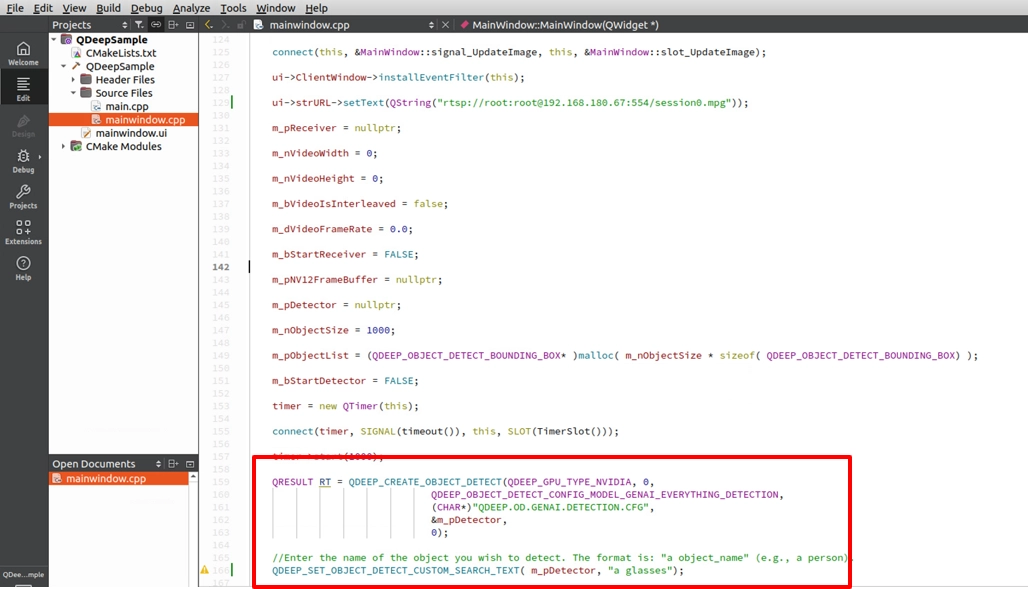
• 検出器作成時の設定を変更する : QDEEP_CREATE_OBJECT_DETECT API で、モデル設定値を専用の QDEEP_OBJECT_DETECT_CONFIG_MODEL_GENAI_EVERYTHING_DETECTION に変更します。
• 新しい API : カスタム検索テキストを理解する。 この API は AI と会話するための橋渡しです。コード内で AI に「何を探すのか」を伝える必要があります。
‧ API 名称 : QDEEP_SET_OBJECT_DETECT_CUSTOM_SEARCH_TEXT
‧ 重要パラメータ pszSearchText : 検出したい物体名を英語文字列で指定します。例 : "a glasses"、 "a cup" など。
QDEEP_CREATE_OBJECT_DETECT
これは AI エンジンを作成し、モデルを読み込むための最も重要な API です。ユーザーはこの API を使用して検出器を初期化する必要があります。

QDEEP_SET_OBJECT_DETECT_CUSTOM_SEARCH_TEXT


QDEEP_OBJECT_DETECT_BOUNDING_BOX 構造体
今回は文字を入力して AI に自由に検出させるため、AI エンジンには固定の分類辞書がありません。そのため、返される構造体内の nClassID will always be 0 になります。


コアコードの作成
10-3 のプロジェクトを開き、最も重要なコード変更を行いましょう。
モデル読み込みを変更し、テキストプロンプトを追加する
mainwindow.cpp のコンストラクタ MainWindow::MainWindow(...) 内で、検出器を作成しているコードを探します。上記のパラメータに置き換え、そのすぐ下で 文字検索 API を呼び出します。今回は AI に面白い課題を与えます。画面内の「メガネ (a glasses)」を探させます。
クラス名を拡張する
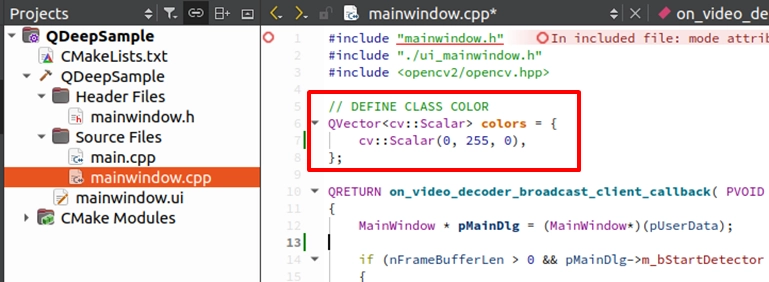
次に、 on_video_decoder_broadcast_client_callback コールバック関数へ移動します。 nClassID は常に 0 なので、配列のラベル名を先ほど API に指定した文字列にそのまま設定すれば問題ありません。
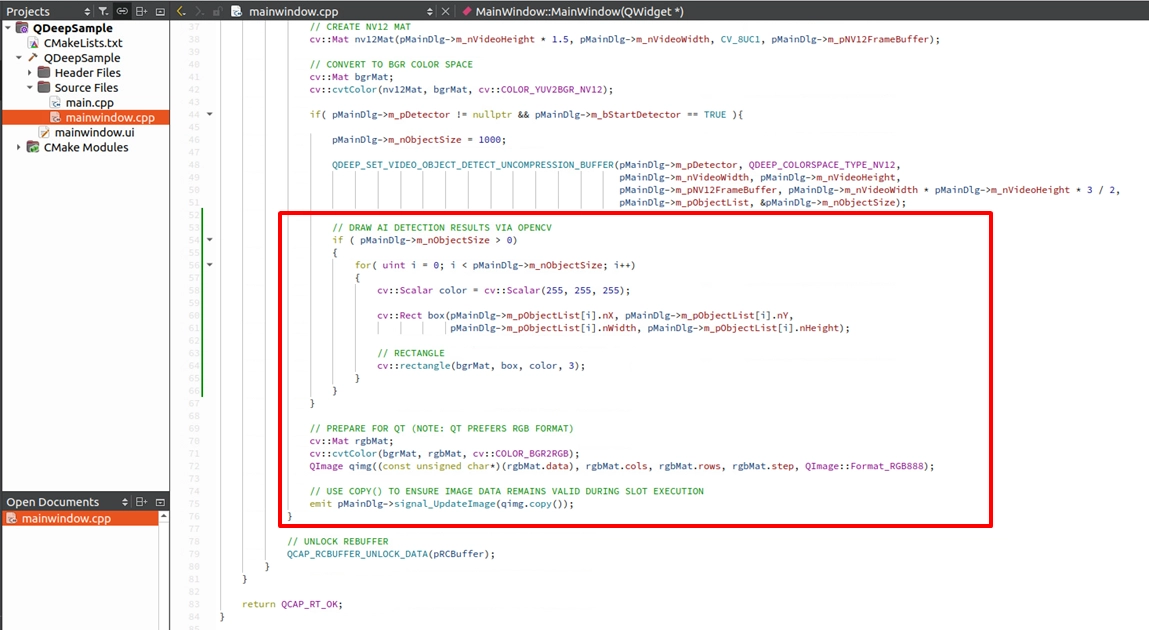
OpenCV を使って認識結果を描画する
最終確認
左下の「Build and RUN」 をクリックしてプロジェクトを実行します。
1. カメラ URL を入力し、 START RECEIVER をクリックして映像を取得します。
2. START DETECTION をクリックします。AI が画面内のメガネを正確に枠で囲むのが確認できます。
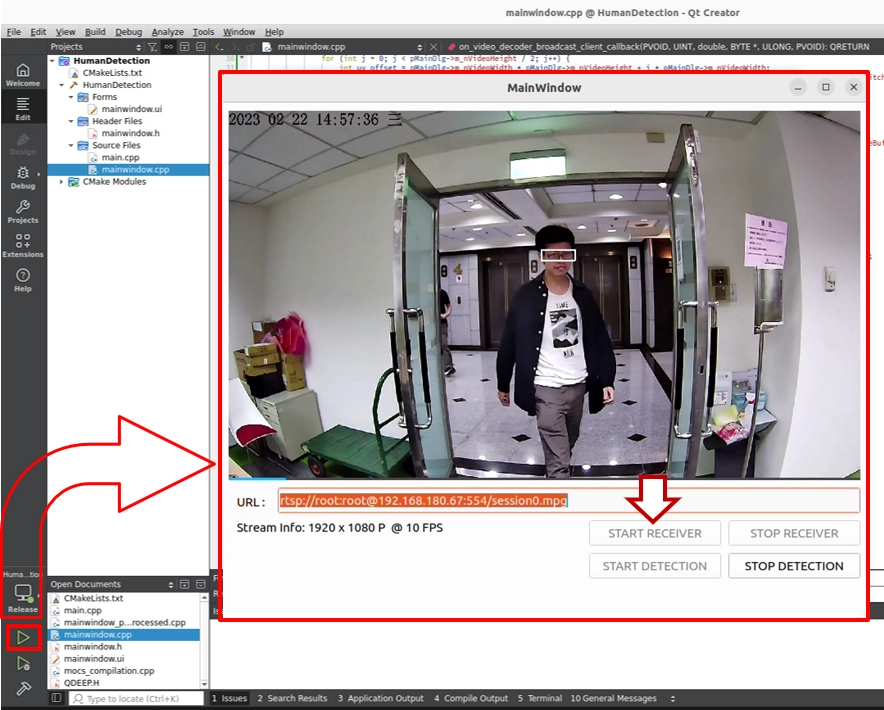
➤ 重要なお知らせ : 初めてこのソフトウェアを 起動する(プログラムを実行する)瞬間、画面が表示されるまで少し時間がかかる場合がありますが、心配しないでください。これは「AI モデルの読み込み」処理をプログラムのコンストラクタ内に書いているためです。初回実行時、モデルは初期化設定を行う必要があり、その間システムは巨大なニューラルネットワークの重みファイルを GPU に読み込んでいます。ソフトウェアが正常に起動すれば、AI の頭脳はバックグラウンドで準備完了です。次回以降は、この初期化待ち時間は不要になります。
これは 10-3 の「人物検出」とほとんど同じに見えますよね? では、いったんプログラムを閉じて、コードに戻り、以下の変更を行ってください。
1. API 内の文字列を「ジャケット」に変更します QDEEP_SET_OBJECT_DETECT_CUSTOM_SEARCH_TEXT(..., "a coat");
2. 再コンパイルして実行します!
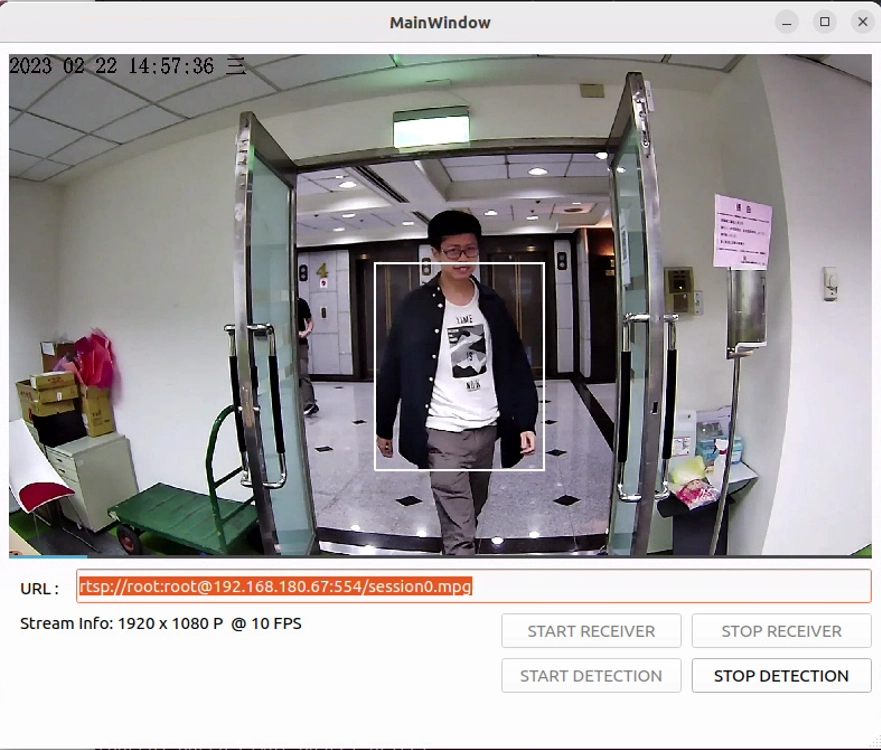
すると、全く再学習を行っていないこのモデルが、なんと即座に検索ターゲットを変更し、画面上のジャケットを正確に枠で囲んでくれることがわかるでしょう!
これこそが画像 AI 分野の最先端技術である「ゼロショット学習 ( Zero-Shot Learning ) 」です。このソフトウェアは、もはや既存の分類辞書に制限されません。コードを 1 行変更するだけで、世界中のあらゆるものを認識できるようになります。